webdancer's Blog
“代码大全”读后感
“我们的精神品德既非与生俱来,也非逆于天性,...,其发展归因于习惯,...,我们要学的东西都通过实际做的过程学到,...,如果人们建的房子好,他们就成为好的建设者;而造的房子不好时,他们就是差的建设者,...,所以小时候养成怎样的习惯关系很大——正是它会造成天壤之别,或者说就是世上所有差异之源。” ——亚里士多德
代码大全旧的内容很多,交给了我们许多软件工程中的解决写软件过程中难题的解决办法。因为自己还没有接触过大型的项目,对于其中的一些并没有很强的共鸣,不过我相信在以后的工作中还是很有用的。下面就简单说一下自己的看书感受:
- 编程需要经验的传授。就像是武侠小说里面一样,一个大侠要练成绝世武功,要么像张无忌一样,偶然的机会得到了像《九阳真经》这样的武功秘籍,要么像郭靖一样,有洪七公这样的前辈教授。他们无不是从前人那里继承了技能和经验,自己发明一门武功的人真的少之又少,编程和练武也一样,很多良好的编程技巧需要学习,代码大全详细的记录了各种技巧,小到如何定义变量名,大到如何管理一个大型的软件项目,都给出了许多建议,这对我们大学生来说,还是挺有用的,很多东西,老师都没讲过。
- 编程是一个渐进的过程。很多时候,我们拿到问题就开始编写代码,这通常并不好。因为一个问题的解决从来都不是那么容易的,而且直接写代码,我们通常需要花费好几倍的时间来调试代码。编程的时候,我们可以先想一下我们要解决的具体问题,首先把问题搞明白,然后再写伪代码,这样我们用自然语言的方式先大体回答了我们要解决的问题(要是在软件工程中,就是一个需求分析,系统设计的过程),然后我们在开始将伪代码转化成代码,这个过程由于前面我们已经解决了很多东西,在这时候我们可以专心写代码。
- 编程需要的东西很多,我们需要逐渐积累。就像建筑师,要积累设计经验一样,我们程序员也要注意积累经验。现在由于搜索引擎太好用了,需要的时候可以搜索,对于很多东西缺乏思考。
- 编程需要好的编程环境和工具。良好的编程工具会极大的提高编程效率,所以一定要为自己选择一个良好的编程环境。
- 这本书是一部大块头,需要的时候翻翻,要一下子消化所有的东西不可能。
python中迭代器和生成器
l=[1,2,3,4]
for n in l:
print n
在看上面这段代码的时候,我们没有显式的控制列表的偏移量,就可以自动的遍历了整个列表对象。那么for 语句是怎么来遍历列表l的呢?要回答这个问题,我们必须首先来看一下迭代器相关的知识。
1.迭代器
迭代器对象要求支持迭代器协议,所谓支持迭代器协议就是对象包含__iter__()和next()方法。其中__iter__()方法返回迭代器对象自己;next()方法返回下一个前进到下一个结果,在结尾时引发StopIteration异常。
列表不是迭代器对象,但是列表通过__iter__()可以得到一个迭代器对象来遍历整个列表的内容,像列表这样的序列对象都属于这种情况;与序列不同,文件对象本身就是一种迭代器对象。
l=[1,2,3,4]
f=open('test.c','r')
iter(l) == l
Out[131]: False
iter (f)== f
Out[132]: True
一个迭代器的例子(来源:python tutorial)
class Reverse:
"""Iterator for looping over a sequence backwards."""
def __init__(self, data):
self.data = data
self.index = len(data)
def __iter__(self):
return self
def next(self):
if self.index == 0:
raise StopIteration
self.index = self.index - 1
return self.data[self.index]
2.生成器
生成器使python可以很容易的支持迭代协议。生成器通过生成器函数产生,生成器函数可以通过常规的def语句来定义,但是不用return返回,而是用yeild一次返回一个结果,在每个结果之间挂起和继续它们的状态,来自动实现迭代协议。
一个生成器的例子(来源:python tutorial)
def reverse(data):
for index in range(len(data)-1, -1, -1):
yield data[index]
3.for语句如何工作
在我们最前面的遍历列表的for语句中,for使用了列表支持迭代器的性质,可以每次通过调用迭代器的next()方法,来遍历到列表中的值,直到遇到StopIteration的异常。
4.注意的问题:
- 像列表这种序列类型的对象,我们可以通过iter()来产生多个迭代器,在迭代的过程中各个迭代器相互对立;但是迭代器对象没法通过iter()方法来产生多个不同的迭代器,它们都指向了自身,所以没法独立使用。
参考: python tutorial, stackoverflow
python的字典类型
前几天复习了hash的相关知识,正好在做udacity的CS101课程用到了python里面的字典,正好复习一下python的字典知识。
1.字典类型基础
python中的字典(dictionary)是一种映射类型,它不同于列表(list)这样的序列类型,它不是以偏移来存取,而是以键来存储,所以字典不支持切片这样的列表操作。
键的类型可以是数字,字符串,不包含可变对象的元组,不能使列表。字典可以被看做一个无序的集合。
常见操作:
1.新建字典;2.添加(键,值)对;3删除(键,值)对;4.由键查找对应的值;5.键,值上循环。
>>> tel = {'jack': 4098, 'sape': 4139}
>>> tel['guido'] = 4127
>>> tel
{'sape': 4139, 'guido': 4127, 'jack': 4098}
>>> tel['jack']
4098
>>> del tel['sape']
>>> tel['irv'] = 4127
>>> tel
{'guido': 4127, 'irv': 4127, 'jack': 4098}
>>> tel.keys()
['guido', 'irv', 'jack']
>>> 'guido' in tel
True
注意问题:序列运算无效;对新键赋值会创建新的项;键值的类型可以不同;避免keyError。
2.为什么列表不能做键
python使用开放散列数据结构实现的。不管是用列表的id还是用列表的内容用来散列,都是符合散列函数的定义的(不同的散列值,不同的键值)。但是这两种方式都存在一些问题:
- 用id散列时,在用不同的键值(id不同),但是内容相同的列表查找时,尽管散列值不同,但是在用列表却相同(满足__equal__)。此外,还有就是列表时一个容器,如果用id散列,意义到底有多大呢?
- 用列表内容散列时,列表内容该更改后,我们会计算出不同的散列值,就会有不同的bucket。
总之,在python中,选择了列表不能做键的策略。我感觉就是既然tuple类型可以用内容来散列,那么我们就不用列表了,列表修改特性会使散列的维护变得很复杂(想想如果我们使用列表的内容散列了,而后我们修改了,我们自己都不知道以前是什么了?如果想要保存以前的内容,不是又做了copy,这样就不如直接用tuple类型了),从而使得这种常用的数据类型的性能出现问题。
注意:用户自定义类型都可以用作键。只要用对象id散列,比较函数用id进行比较。为什么在列表中不可以,但是在自定义类型中就行?一个主要的原因就是对放在字典中的自定义类型来说,id重要,有了id就可以找到内容了。
散列表(hash table)
1.散列表概念
散列表(hash table ,hash map)是一种使用散列函数将“键”映射到“值”的数据结构,这样散列表实现了字典结构。示意图如下:

散列函数(hash function)将“键”转为bucket的索引,正如在上一篇介绍散列函数是说的,一般情况下散列表不是理想散列,会发生“碰撞”(即不同的键映射到了相同的的值)。
使用散列解决的一个核心问题就是查找(search)。散列的思想是是把键的某些内容打乱,使用这种部分的信息作为查找的开始。为了使用散列表,我们需要解决两个问题:寻找散列函数(hash function)和解决“碰撞”。
2.散列函数
一个良好的散列函数要满足两个条件:
- 容易计算。
- 最小化“碰撞”。概率的角度看,就是要求散列函数应该让散列值服从一个均匀分布,一个非均匀的分布,在概率大的地方,显然容易发生“碰撞”。设计一个散列函数,让散列值服从均匀分布是困难的。
设计良好的散列函数一直是一个有挑战性的工作。通常有两种:基于除法和基于乘法。
- 取余法。h(k)=k%M 。M的取值对于散列函数影响较大,通常M取一个素数,使得r^k <> a ,其中r为键字符集合级数,k,a是较小的数。
- 乘法方法。
![]() 其中:w是计算机字数目,A是一个w互素的常数。
其中:w是计算机字数目,A是一个w互素的常数。
3.解决“碰撞”
1.独立拉链。这种解决方法思路很简单,就是将发生“碰撞”的<键,值>对用链表连接起来。如下图:

2.开放寻址。这种方法是确定某种规则,通过它,某个键K来确定一个“探查序列”,即表中的某些位置,每当查找或是插入K时,这些位置就会被探查。最简单的方法是:线性开放寻址散列,即当发生“碰撞”时,把<键,值>对存到下一个可用的bucket中去。如下图:

两种方法比较:
评价准则:负载因子(loading factor): a= n / b 其中:n为元素数目;b为bucket的数目。

更多的信息,大家可以参考wikipedia或是taop。
参考:wikipedia ,taop
认识MD5
MD5是一种安全哈希算法(secure hash algorithm,SHA);SHA是一种加密哈希函数(cryptographic hash function);加密哈希函数是一种哈希函数(hash function); 哈希函数是一种函数。下面我们就看一下这些概念。
1.函数(function)
学习过离散数学,我们对函数并不陌生。不严格地说,在定义域上上的值x,都有值域上唯一的值y与之对应,这种映射关系成为函数。简单地说,函数可以将一些数值变换到另外一些数值(当然可以使本身)。注:数学上的函数与编程语言的函数还是有些不同,虽然在程序中的函数,给定输入(参数),可以得到输出(返回值)两者的范畴感觉还是不太一样。
2.哈希函数(hash function)
散列函数是一种从任何一种数据中创建小的数字“指纹”的方法。哈希函数得到的输出成为散列值。哈希函数是一种特殊的函数,当然满足函数的基本性质,即两个不同的散列值对应的输入时不同的。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。不同的输入映射到相同的散列值称“碰撞”。哈希函数如下图所示:
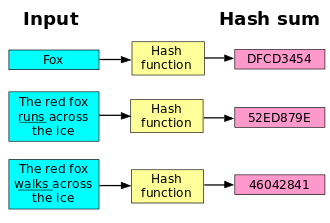
哈希函数的主要应用有:
- 散列表。散列表是一种重要的数据结构,是哈希函数的一个重要应用。使用散列表能够快速的按照关键字查找数据记录。
- 加密。一个典型的加密单向函数是“非对称”的,并且由一个高效的散列函数构成。加密算法可以分为两类: 对称加密和非对称加密
- 错误校正。使用一个散列函数可以很直观的检测出数据在传输时发生的错误。在数据的发送方,对将要发送的数据应用散列函数,并将计算的结果同原始数据一同发送。在数据的接收方,同样的散列函数被再一次应用到接收到的数据上,如果两次散列函数计算出来的结果不一致,那么就说明数据在传输的过程中某些地方有错误了。
- 语音识别,Rabin-Karp 字符串搜索算法等。
3.加密哈希函数(Cryptographic hash function)
加密哈希函数是一种哈希函数,其满足哈希函数的基本性质:将一个大数据转为一个固定bit的字符串。其输入和输出分别成为:message(消息)和digest(摘要)。其中一个良好的加密哈希函数要求一下几点:
- 有消息容易计算摘要。
- 有摘要反向得到消息是不可行的(哈希函数不可逆,单向函数)
- 消息改变,摘要一定改变(哈希函数不碰撞)
- 两个不同的消息,对应不同的摘要(哈希函数不碰撞)
安全哈希函数如下所示:
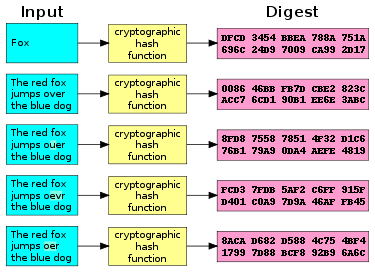
应用:
- 文件或消息完整性验证。
- 文件或数据标识。比如git等代码管理系统使用sha1sum来区分不同内容。
4.安全哈希算法(secure hash algorithm,SHA)
安全散列算法是一种能计算出一个数位讯息所对应到的,长度固定的字串(又称讯息摘要)的算法。SHA家族的五个算法,分别是SHA-1、SHA-224、SHA-256、SHA-384,和SHA-512,由NSA所设计,并由NIST发布;是美国的政府标准。后四者有时并称为SHA-2。
python的hashlib模块中实现了上述五种SHA算法和更早的md5算法。

5.MD5
MD5即Message-Digest Algorithm 5用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一 ,主流编程语言普遍已有MD5实现。
MD5是一种安全哈希算法,但是MD5较老,散列长度通常为128位元,随着计算机运算能力提高,找到“碰撞”是可能的。在加密哈希函数中已经说过,一个良好的加密哈希函数应该不碰撞。2004年,王小云证明MD5数字签名算法可以产生碰撞。
为什么证明产生碰撞,MD5算法就失效了呢?以前不太理解,下面的解释还是比较清楚地。
根据密码学的定义,如果内容不同的明文,通过散列算法得出的结果(密码学称为信息摘要)相同,就称为发生了“碰撞”。散列算法的用途不是对明文加密,让别人看不懂,而是通过对信息摘要的比对,判断原文是否被篡改。所以说对摘要算法来说,它只要能找到碰撞就足以让它失效,并不需要找到原文。具一个例子, Linux的用户安全机制,只要得到用户密码文件(其中记录了密码的MD5),然后随便生成一个碰撞的原文(不一定要跟原密码相同),就可以用这个密码登录了。
参考:wikipedia
#转帖#版本控制入门简介
版本控制已经出现有些年头了。然而,我还是会被人问起一些,诸如版本控制是什么或者它是如何工作的,这样基础的问题。本文会概括地解释版本控制解决的重要问题,本文使用的场景针对的是源代码版本控制。
目前有很多不同类型的版本控制系统(Version Control System, VCS)。一些VCS,比如Subversion和CVS,以中央仓库(repository)为中心进行架构。此外,还有分布式的VCS(Distributed VCS,DVCS), Git 和 Mercurial 是两个新近出现的DVCS。然而,在上述两种类型的环境中,通常会有一个“指定的”中央仓库。对应地,比如一个Subversion服务器或者一个GitHub仓库。下面会基于这个场景进行图示说明。那么让我们开始吧。
在开发者拷贝到本机之前,服务器需要创建一个仓库。创建初始仓库会由于产品不同而有所差别。从现在起,你所要知道的就是,在服务器上有一个初始空间。我把这个版本称作版本“A”。

现在,每个开发者(开发者1和开发者2)都会拷贝版本“A”到他们本地电脑。再一次地,从服务器拷贝的过程会由于产品不同采用的技术会有所差别。 
每个开发者会在他们的本地拷贝上进行开发。他们的本地拷贝基于版本“A”。然而,由于他们应该不会做同样的开发,因而他们的版本会有所差别。因此,会有2个以上的版本会同时被创建,比如版本“B”和版本“C”。 
开发者1首先完成了她的工作并提交到服务器。服务器上的当前版本被更新成版本“B”。 
开发者2现在完成了他的工作并试图提交到服务器。然而,这是服务器告知他基于开发的版本已经发生改变。这也是为什么采取版本控制的首要原因之一。这个特性是对网络共享代码然后由开发者手动更新的一个跨越式发展,这确保了之前的编辑没有被新的修改覆盖。 
开发者2必须首先获得所有版本“B”的变化,并合并到他的修改中,然后才可以提交到服务器。这个过程听起来有些复杂。然而,大多数现代的版本控制系统十分高级,能够自动在开发者的本地拷贝上完成合并。有几种情况会产生冲突(例如:开发者1和开发者2同时修改了同一个文件的同一行)。这就是一些VCS产品比其他更高级的地方。不论如何完成合并,现在开发者2在他们的本地系统上同时混合了版本B和版本C。 
现在开发者2可以提交他的版本到服务器。 
这是一个版本控制的基础。通过注意观察图中服务器的连线可以发现版本控制的原理。服务器记录了所有先前的版本包括发生的变化,什么时候发生以及由谁进行修改。当需要进行代码回溯或者引入其他bug时,这个记录能够解除困境。
我希望本文能够为版本控制系统提供一个基础的介绍。如果你有任何疑问,请就你问题发表评论。
#转帖#成为Python高手
本文是从 How to become a proficient Python programmer 这篇文章翻译而来。
- 函数式编程
- 性能
- 测试
- 编码规范
shuffling(洗牌)
Shuffling is a procedure used to randomize a deck of playing cards to provide an element of chance in card games. —wikipedia
To shuffle an array a of n elements (indices 0..n-1):
for i from n − 1 downto 1 do
j ← random integer with 0 ≤ j ≤ i
exchange a[j] and a[i]
python代码实现:
def fyshuffling(a):
for i in range(len(a)-1,0,-1):
j=random.randint(0,i)
a[i],a[j]=a[j],a[i]