webdancer's Blog
c函数指针
//声明整数相加函数
int add_int(int a, int b)
{
return a + b;
}
//声明浮点数相加函数
float add_float(float a, float b)
{
return a+b;
}
//定义函数指针类型
typedef int (*int_add_funtion)(int a,int b);
//定义函数指针类型
typedef float (*float_add_funtion)(float a , float b);
int main()
{
//声明一个函数指针,名字叫做int_add_fun,相当于创建int_add_funtion这个类型的实例,下同
int_add_funtion int_add_fun;
//声明一个函数指针,名字叫做float_add_fun
float_add_funtion float_add_fun;
//将该函数指针指向 整数相加函数 的入口地址
int_add_fun = add_int;
//将该函数指针指向 浮点数相加函数 的入口地址
float_add_fun = add_float;
//以常规方式调用 整数相加函数,打印出100+200的计算结果
printf("%d\n", add_int(100,200));
//用函数指针调用 整数相加函数,打印出100+200的计算结果
printf("%d\n", (*int_add_fun)(100,200));
//以常规方式调用 浮 点数相加函数,打印出100.32 + 324.54的计算结果
printf("%f\n", add_float(100.32f, 324.54f));
//用函数指针调用 浮点数相加函数,打印出 100.32 + 324.54的计算结果
printf("%f", (*float_add_fun)(100.32f, 324.54f));
return 0;
}
大数乘法,加法,除法运算 (转)
大数乘法,加法,除法
/* 写写大整数的一些算法,网上也可以找到,不过没有完整的
* 程序,于是写写比较完整的程序,发在Blog上
*/
#include <stdio.h>
#define MAXINT 1000
int compare(int a[],int b[]);
int bigplus(int a[],int b[],int c[]);
int bigsub(int a[],int b[],int c[]);
int bigmult(int a[],unsigned int b,int c[]);
int bigmult2(int a[],int b[],int c[]);
int bigdiv(int a[],unsigned int b,int c[],int *d);
int bigdiv2(int a[],int b[],int c[],int d[]);
int main(int argc, char *argv[])
{
int a[MAXINT]={10,5,4,6,5,4,3,2,1,1,1}; //被乘数或被除数
int b[MAXINT]={7,7,6,5,4,3,2,1}; //乘数或除数
int c[MAXINT],d[MAXINT]; //c[]存放商,d[]存放余数
int div=1234; //小乘数或小除数
int k=0;
int *res=&k; //小余数整数指针
bigplus(a,b,c);
bigsub(a,b,c);
bigmult(a,div,c);
bigmult2(a,b,c);
bigdiv(a,div,c,res);
bigdiv2(a,b,c,d);
getchar();
return 0;
}
int compare(int a[],int b[]) //比较大整数的大小
{
int i;
if (a[0]>b[0]) return 1; //比较a,b的位数确定返回值
else if (a[0]<b[0]) return -1;
else //位数相等时的比较
{
i=a[0];
while (a[i]==b[i]) //逐位比较
i--;
if (i==0) return 0;
else if (a[i]>b[i]) return 1;
else return -1;
}
}
int bigplus(int a[],int b[],int c[]) //大整数加法
{
int i,len;
len=(a[0]>b[0]?a[0]:b[0]); //a[0] b[0]保存数组长度,len为较长的一个
for(i=0;i<MAXINT;i++) //将数组清0
c[i]=0;
for (i=1;i<=len;i++) //计算每一位的值
{
c[i]+=(a[i]+b[i]);
if (c[i]>=10)
{
c[i]-=10; //大于10的取个位
c[i+1]++; //高位加1
}
}
if (c[i+1]>0) len++;
c[0]=len; //c[0]保存结果数组实际长度
printf("Big integers add: ";
for (i=len;i>=1;i--)
printf("%d",c[i]); //打印结果
printf("\n";
return 0;
}
int bigsub(int a[],int b[],int c[]) //大整数减法
{
int i,len;
len=(a[0]>b[0]?a[0]:b[0]); //a[0]保存数字长度,len为较长的一个
for(i=0;i<MAXINT;i++) //将数组清0
c[i]=0;
if (compare(a,b)==0) //比较a,b大小
{
printf("Result:0";
return 0;
}
else if (compare(a,b)>0)
for (i=1;i<=len;i++) //计算每一位的值
{
c[i]+=(a[i]-b[i]);
if (c[i]<0)
{
c[i]+=10; //小于0的原位加10
c[i+1]--; //高位减1
}
}
else
for (i=1;i<=len;i++) //计算每一位的值
{
c[i]+=(b[i]-a[i]);
if (c[i]<0)
{
c[i]+=10; //小于0原位加10
c[i+1]--; //高位减1
}
}
while (len>1 && c[len]==0) //去掉高位的0
len--;
c[0]=len;
printf("Big integers sub= ";
if (a[0]<b[0]) printf("-";
for(i=len;i>=1;i--) //打印结果
printf("%d",c[i]);
printf("\n";
return 0;
}
int bigmult(int a[],unsigned int b,int c[])//高精度乘以低精度
{
int len,i;
for (i=0;i<MAXINT;i++) //数组清0
c[i]=0;
len=a[0];
for(i=1;i<=len;i++) //对每一位计算
{
c[i]+=a[i]*b;
c[i+1]+=c[i]/10;
c[i]%=10;
}
while (c[++len]>=10) //处理高位
{
c[len+1]=c[len]/10;
c[len]%=10;
}
if (c[len]==0) len--; //处理高进位为0情况
printf("Big integrs multi small integer: ";
for (i=len;i>=1;i--)
printf("%d",c[i]);
printf("\n";
}
int bigmult2(int a[],int b[],int c[]) //高精度乘以高精度
{
int i,j,len;
for (i=0;i<MAXINT;i++) //数组清0
c[i]=0;
for (i=1;i<=a[0];i++) //被乘数循环
for (j=1;j<=b[0];j++) //乘数循环
{
c[i+j-1]+=a[i]*b[j]; //将每一位计算累加
c[i+j]+=c[i+j-1]/10; //将每一次结果累加到高一位
c[i+j-1]%=10; //计算每一次的个位
}
len=a[0]+b[0]; //取最大长度
while (len>1 && c[len]==0) //去掉高位0
len--;
c[0]=len;
printf("Big integers multi: ";
for (i=len;i>=1;i--) //打印结果
printf("%d",c[i]);
printf("\n";
}
int bigdiv(int a[],unsigned int b,int c[],int *d) //高精度除以低精度
{ //a[] 为被乘数,b为除数,c[]为结果,d为余数
int i,len;
len=a[0]; //len为a[0]的数组长度
for (i=len;i>=1;i--)
{
(*d)=10*(*d)+a[i]; //计算每一步余数
c[i]=(*d)/b; //计算每一步结果
(*d)=(*d)%b; //求模余数
}
while (len>1 && c[len]==0) len--; //去高位0
printf("Big integer div small integer: ";
for (i=len;i>=1;i--) //打印结果
printf("%d",c[i]);
printf("\tArithmetic compliment:%d",*d);
printf("\n";
}
int bigdiv2(int a[],int b[],int c[],int d[]) //高精度除以高精度
{
int i,j,len;
if (compare(a,b)<0) //被除数较小直接打印结果
{
printf("Result:0";
printf("Arithmetic compliment:";
for (i=a[0];i>=1;i--) printf("%d",a[i]);
printf("\n";
return -1;
}
for (i=0;i<MAXINT;i++) //商和余数清0
{
c[i]=0;
d[i]=0;
}
len=a[0];d[0]=0;
for (i=len;i>=1;i--) //逐位相除
{
for (j=d[0];j>=1;j--)
d[j+1]=d[j];
d[1]=a[i]; //高位*10+各位
d[0]++; //数组d长度增1
while (compare(d,b)>=0) //比较d,b大小
{
for (j=1;j<=d[0];j++) //做减法d-b
{
d[j]-=b[j];
if (d[j]<0)
{
d[j]+=10;
d[j+1]--;
}
}
while (j>0 && d[j]==0) //去掉高位0
j--;
d[0]=j;
c[i]++; //商所在位值加1
}
}
j=b[0];
while (c[j]==0 && j>0) j--; //求商数组c长度
c[0]=j;
printf("Big integers div result: ";
for (i=c[0];i>=1;i--) //打印商
printf("%d",c[i]);
printf("\tArithmetic compliment: "; //打印余数
for (i=d[0];i>=1;i--)
printf("%d",d[i]);
printf("\n";
}
trie tree (转)
Trie,又称字典树、单词查找树,是一种树形结构,用于保存大量的字符串。它的优点是:利用字符串的公共前缀来节约存储空间。
相对来说,Trie树是一种比较简单的数据结构.理解起来比较简单,正所谓简单的东西也得付出代价.故Trie树也有它的缺点,Trie树的内存消耗非常大.当然,或许用左儿子右兄弟的方法建树的话,可能会好点.
其基本性质可以归纳为:
1. 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2. 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3. 每个节点的所有子节点包含的字符都不相同。
其基本操作有:查找 插入和删除,当然删除操作比较少见.我在这里只是实现了对整个树的删除操作,至于单个word的删除操作也很简单.
搜索字典项目的方法为:
(1) 从根结点开始一次搜索;
(2) 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索;
其他操作类似处理.
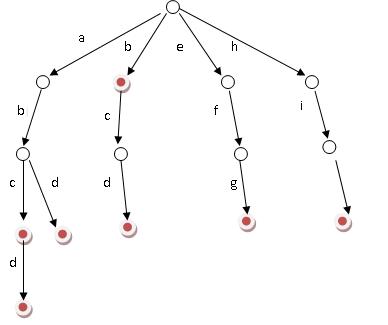
Name: Trie树的基本实现
Author: MaiK
Description: Trie树的基本实现 ,包括查找 插入和删除操作*/
#include<algorithm>
#include<iostream>
using namespace std;
const int sonnum=26,base='a';
struct Trie
{
int num;//to remember how many word can reach here,that is to say,prefix
bool terminal;//If terminal==true ,the current point has no following point
struct Trie *son[sonnum];//the following point
};
Trie *NewTrie()// create a new node
{
Trie *temp=new Trie;
temp->num=1;temp->terminal=false;
for(int i=0;i<sonnum;++i)temp->son[i]=NULL;
return temp;
}
void Insert(Trie *pnt,char *s,int len)// insert a new word to Trie tree
{
Trie *temp=pnt;
for(int i=0;i<len;++i)
{
if(temp->son[s[i]-base]==NULL)temp->son[s[i]-base]=NewTrie();
else temp->son[s[i]-base]->num++;
temp=temp->son[s[i]-base];
}
temp->terminal=true;
}
void Delete(Trie *pnt)// delete the whole tree
{
if(pnt!=NULL)
{
for(int i=0;i<sonnum;++i)if(pnt->son[i]!=NULL)Delete(pnt->son[i]);
delete pnt;
pnt=NULL;
}
}
Trie* Find(Trie *pnt,char *s,int len)//trie to find the current word
{
Trie *temp=pnt;
for(int i=0;i<len;++i)
if(temp->son[s[i]-base]!=NULL)temp=temp->son[s[i]-base];
else return NULL;
return temp;
}
os实验--进程的调度
Linux系统中,进程的调度策略其实是一个比较困难的问题,实验指导书上的只是很不全面,而且模棱两可。现在只能大致了解一下: 通用Linux系统支持实时和非实时两种进程,实时进程相对于普通进程具有绝对的优先级。 通用Linux系统支持实时和非实时两种进程,实时进程相对于普通进程具有绝对的优先级。对应地,实时进程采用SCHED_FIFO或者SCHED_RR调度策略,普通的进程采用SCHED_OTHER调度策略。
优先级:
非实时进程有两种优先级,一种是静态优先级,另一种是动态优先级。实时进程又增加了第三种优先级,实时优先级。优先级是一些简单的整数,它代表了为决定应该允许哪一个进程使用 CPU 的资源时判断方便而赋予进程的权值——优先级越高,它得到 CPU 时间的机会也就越大:
1 .静态优先级——被称为“静态”是因为它不随时间而改变,只能由用户进行修改。它指明了在被迫和其它进程竞争 CPU 之前该进程所应该被允许的时间片的最大(但是也可能由于其它原因,在该时间片耗尽之前进程就被迫交出了 CPU。)值。
2.动态优先级——只要进程拥有 CPU,它就随着时间不断减小;当它小于 0 时,标记进程重新调度。它指明了在这个时间片中所剩余的时间量。
3.实时优先级——指明这个进程自动把 CPU 交给哪一个其它进程:较高权值的进程总是优先于较低权值的进程。因为如果一个进程不是实时进程,其优先级就是 0,所以实时进程总是优先于非实时进程的。
(这并不完全正确;如同后面论述的一样,实时进程也会明确地交出 CPU,而在等待 I/O 时也会被迫交出 CPU。前面的描述
仅限于能够交付 CPU 运行的进程).
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<sys/types.h>
#include<signal.h>
#include<sched.h>
#include<sys/times.h>
#include<sys/resource.h>
typedef void (*sighandler_t)(int);
void sigcon(){
pid_t pi=getpid();
int pj=getpriority(PRIO_PROCESS,pi);
setpriority(PRIO_PROCESS,pi,pj+1);
printf("the pid is : %d ,the priority is %d,after SIGINT the priority is : %d\n",pi,pj,pj+1);
}
void sigcon1(){
pid_t pi=getpid();
int pj=getpriority(PRIO_PROCESS,pi);
setpriority(PRIO_PROCESS,pi,pj-1);
printf("the pid is : %d ,the priority is %d,after SIGTSTP the priority is : %d\n",pi,pj,pj-1);
}
int main(){
pid_t p0;
signal(SIGINT,(sighandler_t)sigcon);
signal(SIGTSTP,(sighandler_t)sigcon1);
int index;
if((p0=fork())<0){
perror("error!");
exit(0);
}
else if(p0==0){
for(index=0;index<4;index++){
pid_t cp=getpid();
int chpriority=getpriority(PRIO_PROCESS,cp);
int schednum=sched_getscheduler(cp);
printf("the child pid is : %d , the priority is : %d , the sched is : %d \n",cp,chpriority,schednum);
kill(cp,SIGINT);
// kill(cp,SIGTSTP);
}
}
else{
int in;
for(in=0;in<4;in++){
pid_t pp=getpid();
int ppriority=getpriority(PRIO_PROCESS,pp);
int pschednum=sched_getscheduler(pp);
printf("the parent pid is : %d , the priority is : %d , the sched is : %d \n",pp,ppriority,pschednum);
kill(pp,SIGINT);
// kill(pp,SIGTSTP);
}
}
return 0;
}
os实验--线程的创建
Linux 利用了特有的内核函数__clone 实现了一个叫 phread 的线程库,__clone是 fork 函数的替代函数,通过更多的控制父子进程共享哪些资源而实现了线程。Pthread 是一个标准化模型,用它可把一个程序分成一组能够并发执行的多个任务。phread 线程库是 POSIX 线程标准的实现,它提供了 C 函数的线程调用接口和数据结构。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
int tjobs0(int );
int tjobs1(int );
pthread_t thr0,thr1;
int num0,num1;
int main(int argc,char * argv[]){
int result;
int ret0,ret1;
int x,y;
printf("input the x and y\n");
printf("input x: ");
scanf("%d",&x);
printf("input y: ");
scanf("%d",&y);
ret0=pthread_create(&thr0,NULL,(void*)tjobs0,(void * )x);
if(ret0<0){
perror("error!");
exit(0);
}
ret1=pthread_create(&thr1,NULL,(void *)tjobs1,(void *)y);
if(ret1<0){
perror("error!");
exit(0);
}
pthread_join(thr0,NULL);
pthread_join(thr1,NULL);
result=num0+num1;
printf("the result is %d\n",result);
return 0;
}
int tjobs0(int i){
if(i==1)
num0=1;
else if(i>1){
num0=tjobs0(i-1)*i;
i--;
}
return num0;
}
int tjobs1(int j){
if(j==1||j==2)
num1=1;
else if(j>2){
num1=tjobs1(j-1)+tjobs1(j-2);
j--;
}
return num1;
}
gcc :gcc是GNU计划的c /c++的编译器。
gcc的用法(详细:info gcc ):
-E: 预处理。
-S:z只编译,不汇编,生成汇编代码。
-c:编译或者汇编,但不链接。
-o:输出到指定文件。
ubuntu 10.4倒计时
ubuntu又快有新版本!

重新拾起c——符号
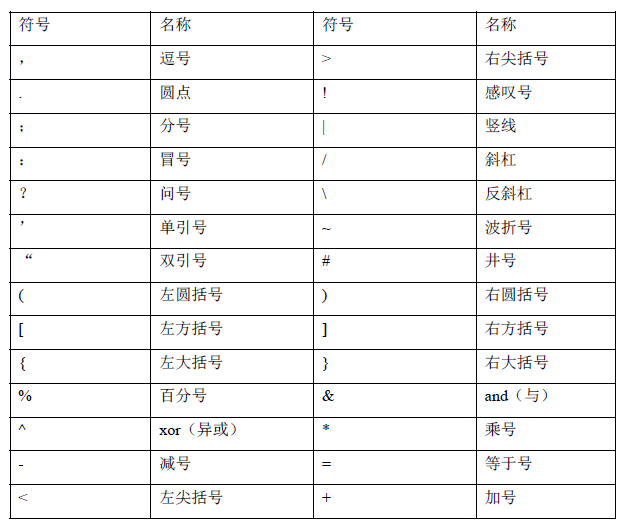
以上为符号的列表。对符号我们就是知道他们经常用的意思!
注意:
1)/* :是注释号,编译器会自动寻找*/与之匹配。int i = 8; int * pi=&i; int j=i/*pi; j的定义有问题。应为:j=i/(*pi);
2)对一个新手来说,注释可能很重要!要写好。
3)\:持续符和转义符。
转义字符转义字符的意义
\n 回车换行
\t 横向跳到下一制表位置
\v 竖向跳格
\b 退格
\r 回车
\f 走纸换页
\\ 反斜扛符"\"
\' 单引号符
\a 鸣铃
\ddd 1~3 位八进制数所代表的字符
\xhh 1~2 位十六进制数所代表的字符
4)逻辑运算符:
&& ,|| :自动判断,如果前面可以判定真假,后面就不理会了。
5)位运算符:
& 按位与
| 按位或
^ 按位异或
~ 取反
<< 左移
>> 右移
位运算符对底层编程很重要。
6)++,--。
有些人不建议使用++,--。因为很多时候,非常容易造成错误!其实,就是优先级问题。对优先级加括号应该是一个好方法!
8)优先级:
尽管我们可以通过加括号來控制,但是阅读他人的代码,还是很有用!
| Operator(s) | Description | Associativity | |
|
17
|
:: | global scope (unary) |
right-to-left
|
|
17
|
:: | class scope (binary) |
left-to-right
|
|
16
|
-> . | member selectors |
left-to-right
|
|
16
|
[ ] | array index |
left-to-right
|
|
16
|
( ) | function call |
left-to-right
|
|
16
|
( ) | type construction |
left-to-right
|
|
16
|
sizeof | size in bytes |
left-to-right
|
|
15
|
++ -- | increment, decrement |
right-to-left
|
|
15
|
~ | bitwise NOT |
right-to-left
|
|
15
|
! | logical NOT |
right-to-left
|
|
15
|
+ - | unary plus, minus |
right-to-left
|
|
15
|
* & | dereference, address-of |
right-to-left
|
|
15
|
( ) | cast |
right-to-left
|
|
15
|
new delete | free store management |
right-to-left
|
|
14
|
->* .* | member pointer selectors |
left-to-right
|
|
13
|
* / % | multiplicative operators |
left-to-right
|
|
12
|
+ - | arithmetic operators |
left-to-right
|
|
11
|
<< >> | bitwise shift |
left-to-right
|
|
10
|
< <= > >= | relational operators |
left-to-right
|
|
9
|
== != | equality, inequality |
left-to-right
|
|
8
|
& | bitwise AND |
left-to-right
|
|
7
|
^ | bitwise exclusive OR |
left-to-right
|
|
6
|
| | bitwise inclusive OR |
left-to-right
|
|
5
|
&& | logical AND |
left-to-right
|
|
4
|
|| | logical OR |
left-to-right
|
|
3
|
? : | arithmetic if |
left-to-right
|
|
2
|
= *= /* %= += -= |
assignment operators |
right-to-left
|
|
1
|
, | comma operator |
left-to-right
|
当然,得经常调试代码!




重新拾起C(1)-关键字
前记: 以前自学的C语言,但是很肤浅!决定,再认真地学一遍。认真的看看C语言,学习的书是陈正冲老师的《C语言深度解析》。套用一句话,永远给我记住一点:结果对,并不代表程序真正没有问题。
c 的关键字:
| auto | break | case | char | const | continue | default | do |
| double | else | enum | extern | float | for | goto | if |
| int | long | register | return | short | signed | sizeof | static |
| struct | switch | typedef | union | unsigned | void | volatile | while |
2)register:寄存器变量修饰,其变量必须是单一的值,且不能用&,取得地址。
3)static:静态修饰符,只能被本文件引用,其他文件不可用。
4)short:短整型。
3)int:整型。
4)long:长整型。
5)float:单精度浮点数。
6)double:双精度浮点数。
7)char:字符类型。
8)enum:枚举类型。(应该是基本类型吧!)
enum ColorT {red, orange, yellow, green, blue, indigo, violet};
...
ColorT c1 = indigo;
if( c1 == indigo ) {
cout << "c1 is indigo" << endl;
}
8)struct:结构体。
struct Date {
int day;
int month;
int year;
} today;
9)union:共用体。
union Data {
int i;
char c;
};
10)void:函数,返回值为空。指针,可以指向任何类型数据。
11)sizeof:计算参数大小。
12)signed:有符号。
13)unsigned:无符号。
14)if :条件。
15)else:其他,条件语句。
16)switch:条件分支语句。
17)case:条件分支语句。
18)do :循环语句。
19) while :循环语句。
20)for:循环语句。
21)break:跳出循环体。
22)continue:结束本次循环,进入下次循环。
23)goto:跳转语句,应该禁用,破坏结构化。当然,还是自己的习惯!
24)return:返回值。
25)const:常量,在c与c++有区别。
26)volatile:可变的,编译器不会自作主张优化其声明的变量。
27)extern :可以置于变量或者函数前,以标示变量或者函数的定义在别的文件
28)typedef:分一个新名字,与原来的一样用。
typedef unsigned int* pui_t;
// data1 and data2 have the same type
pui_t data1;
unsigned int* data2;