编程语言 - webdancer's Blog
Scala--基本类型和操作
1.类型:Scala的基本类型与Java中的Primitive type对应起来,不过都是首字母大写的类,例如Byte,Short,Int,Long,Char,Float,Double,String,Boolean
2.字面值(literal):在代码中直接写常数值的一种方式。这个Scala与Java基本相同。但是Scala提供Symbol字面值。
1 | val s='type |
3.操作:对于大部分操作符来说,与Java相同,但是“==”不同。在Scala中,"=="首先判断“==”左边是否是null,如果不是null然后条用equals方法。
4.Scala给基本类型提供了Rich Wrapper,可以有更加丰富的方法。
Scala学习-类,对象
1.类:类是对象的蓝图,根据类,使用new关键字,就可以创建对象了。和Java一样,Scala的对象也包含:属性和方法。这部分和Java基本上相同。
- 属性:默认是public的,使用private可以改变作用域;
-
方法:定义类的方法与定义普通的相同;Scala没有静态方法。
12345
classChecksumAccumulator {privatevarsum=0defadd(b:Byte) { sum +=b }defchecksum():Int=~ (sum &0xFF) +1}
在Scala的代码中,一个语句如果单独一行的话,可以不加分号,自动进行分号的推断;
- class可以带参数,class Rational(a:Int,b:Int)
- 使用override进行函数重载:
-
123
classRational(a:Int,b:Int){overrridedeftoString=a +"/"+ b} - preconditions:可以使用require()。
1 2 3 4 5 6 7 8 9 10 | class Rational(a:Int, b:Int){ require(b != 0) val numer:Int = a val demon:Int = b override def toString = a + "/" + b def add(that: Rational) = new Rational( a * that.demon + b * that.numer, b * that.demon )} |
2.使用object定义singleton 对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | import scala.collection.mutable.Mapobject ChecksumAccumulator { private val cache = Map[String, Int]() def calculate(s: String): Int = if (cache.contains(s)) cache(s) else { val acc = new ChecksumAccumulator for (c <- s) acc.add(c.toByte) val cs = acc.checksum() cache += (s -> cs) cs}} |
Singleton与class的名字相同,他们得放在同一源文件中,称为companion class 与companion object。不会创建新的类型;与class的名字不同,称为standalone对象,这种对象可以作为一个Scala程序的启动点。
3.Scala程序的启动类似Java,使用含有main方法的Singleton对象。
运行程序的话,首先使用scalac或是fsc进行编译,然后使用scala运行(不含后缀),终于Java的命令行是类似的。
也可是使用Application traits来启动程序,不过这种方法仅仅用在一些简单的,单线程程序中。
Scala学习-语言基础
1.Scala解释器:键入scala命令启动,使用和python的差不多;也可以运行脚本文件:
scala xx.scala
2.变量定义:两种变量类型:val和var,val类型变量一旦初始化,不能再被赋值,相当于java中的final类型的变量。与java不同的是Scala可以进行类型推导,不用显示的写出变量的类型。
1 2 | var a = "Hello World"val b = 3.14 |
如同想要显示的写出变量类型,可以在变量名称后面加上“:type”:
1 2 | var a:String = "Hello World"val b:Int = 3.14 |
3.函数定义:
scala的函数定义用"def"作为开始的标识符,
1 2 3 4 5 6 | def max(a:Int, b:Int):Int = { if (a>b) a else b} |
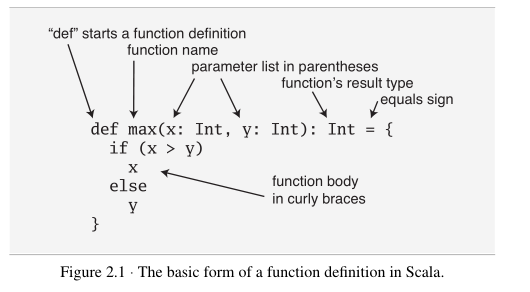
需要注意:函数的返回值在非递归函数时可以省去,但是作为良好的编程习惯,还是加上;在只有一个语句的情况下,大括号可以省略。
1 | def error = println("Error!") |
Scala的函数参数传递方式一般是CBV(call by value),如果参数类型前面有“=>”则使用CBN(call by name)。
4.控制结构:可以用while进行循环,if进行判断,与java一样的。
5.使用foreach和for来进行迭代:
函数时first citizen,可以充当参数,所以foreach的参数可以是function literal。例如如果输出脚本的参数,
1 | args.foreach((arg:String) => println(arg)) |
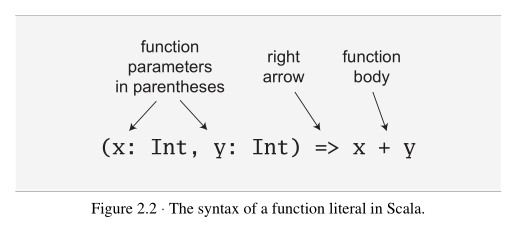
也可以使用for,
1 2 | for(arg <- args) println(arg) |
python的namespace问题
1.问题
写程序的时候,出现了一个bug,看了很久也没有发现问题。程序的逻辑模样大致如下所示:
1 2 3 4 | for i in range(4): x = [ e**i for i, e in enumerate(range(5))] y = 2 * i print y |
如果对python很熟悉的,一眼就可以看出问题的所在。程序的原意是:y = 2 * i 这条语句中i与第一行中的i一致的,但是却使用了第二行中的i值,但是程序依然循环了四次。打印的结果是:
1 2 3 4 | 8888 |
这令人非常的疑惑,主要是在python 2,x中,list comprehension中的变量的scope没有仅限于‘[ ]’中,而是漏了出来。这的确有点不太符合逻辑,因为在理解上,‘[ ]’中的变量的scope仅限于里面,更加符合直观的感觉。
2.解决
解决的方法:
- 避免名字冲突就行了,比如把第二行的i换成j。
- 升级python的版本。在python 3.x中,这个问题就不存在了,list comprehension表达式有了自己的scope.(是不是应该升级到python 3了??但是好像一些包还是支持3.x不太好呀,囧。。。)
3.python 的namespace和scope
namespace就是一个从名字到对象的映射,现在的python好像就是用字典数据结构实现的。对于namespace注意的就是生命周期(lifetime)和作用域(scope)。所谓生命周期就是实现namespace的对象在内存中存在的时间,而作用域(scope)就是namespace在程序中起作用的文本区域。
理解过程抽象
在学习编程的过程中,一个核心的任务是编写可以完成我们任务的函数。不管我们使用的什么语言,做什么开发,函数抽象并不少见。所谓的函数,我认为就是一些语句的集合,完成一个特定的任务。有了函数,我们思维时的操作原子型的层次变的比较高,思维的难度就会降低。但是在不同的编程实践中,为了完成任务需要的编写函数的思维方式也许是不同的,这会受到编程语言或是第三方库的影响。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include<stdio.h> void swap_int(int * a, int * b){ int tmp=0; tmp=*a; *a=*b; *b=tmp; } void bubblesort(int * a,int n){ int i; int j; for(i=0;i<n-1;i++){ for(j=n-1;j>i;j--){ if (a[j]<a[j-1]){ swap_int(&a[j],&a[j-1]); } } } } |
1 2 3 4 5 6 | def bubblesort(l): n=len(l) for i in range(n-1): for j in range(n-1,i,-1): if l[j]<l[j-1]: l[j],l[j-1]=l[j-1],l[j] |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | public class BubbleSort{ public static void sort(int[] l){ int n=l.length; for(int i=0;i<n;i++){ for(int j=n-1;j>i;j--){ if(l[j]<l[j-1]){ swap_int(l,j,j-1); } } } } private static void swap_int(int[] l,int m,int n){ int tmp=l[m]; l[m]=l[n]; l[n]=tmp; }} |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | (define (bubblesort l) (let ((n (vector-length l))) (map (lambda (i) (map (lambda (j) (if (<; (vector-ref l j) (vector-ref l (- j 1))) (swap l j (- j 1)))) (range (- n 1) i -1))) (range 0 n 1))))(define (swap l a b) (let ((tmp (vector-ref l a))) (vector-set! l a (vector-ref l b)) (vector-set! l b tmp)))(define (range low high step) (if (or (and (>; step 0) (> low (- high 1))) (and (< step 0) (< low (+ high 1)))) () (cons low (range (+ low step) high step))))(define l (vector 2 3 1 5 4 7 8 9 1))(bubblesort l)(display l) |
- 过程抽象对于我们解决问题,非常有用。使用高级语言提供的机制,可以大大解放我们的编程效率。
- 理解问题的时候,通常没法子一下理解的很好,所以在对问题的理解上,要多花功夫。
- 在写过程式的语言时,对于一些地方很模糊,这就是我们训练的地方。
- 函数式的编程方式,对思维的训练量很大。
python中迭代器和生成器
1 2 3 4 | l=[1,2,3,4]for n in l: print n |
在看上面这段代码的时候,我们没有显式的控制列表的偏移量,就可以自动的遍历了整个列表对象。那么for 语句是怎么来遍历列表l的呢?要回答这个问题,我们必须首先来看一下迭代器相关的知识。
1.迭代器
迭代器对象要求支持迭代器协议,所谓支持迭代器协议就是对象包含__iter__()和next()方法。其中__iter__()方法返回迭代器对象自己;next()方法返回下一个前进到下一个结果,在结尾时引发StopIteration异常。
列表不是迭代器对象,但是列表通过__iter__()可以得到一个迭代器对象来遍历整个列表的内容,像列表这样的序列对象都属于这种情况;与序列不同,文件对象本身就是一种迭代器对象。
1 2 3 4 5 6 7 8 | l=[1,2,3,4]f=open('test.c','r')iter(l) == lOut[131]: Falseiter (f)== fOut[132]: True |
一个迭代器的例子(来源:python tutorial)
1 2 3 4 5 6 7 8 9 10 11 12 | class Reverse: """Iterator for looping over a sequence backwards.""" def __init__(self, data): self.data = data self.index = len(data) def __iter__(self): return self def next(self): if self.index == 0: raise StopIteration self.index = self.index - 1 return self.data[self.index] |
2.生成器
生成器使python可以很容易的支持迭代协议。生成器通过生成器函数产生,生成器函数可以通过常规的def语句来定义,但是不用return返回,而是用yeild一次返回一个结果,在每个结果之间挂起和继续它们的状态,来自动实现迭代协议。
一个生成器的例子(来源:python tutorial)
1 2 3 | def reverse(data): for index in range(len(data)-1, -1, -1): yield data[index] |
3.for语句如何工作
在我们最前面的遍历列表的for语句中,for使用了列表支持迭代器的性质,可以每次通过调用迭代器的next()方法,来遍历到列表中的值,直到遇到StopIteration的异常。
4.注意的问题:
- 像列表这种序列类型的对象,我们可以通过iter()来产生多个迭代器,在迭代的过程中各个迭代器相互对立;但是迭代器对象没法通过iter()方法来产生多个不同的迭代器,它们都指向了自身,所以没法独立使用。
参考: python tutorial, stackoverflow
python的字典类型
前几天复习了hash的相关知识,正好在做udacity的CS101课程用到了python里面的字典,正好复习一下python的字典知识。
1.字典类型基础
python中的字典(dictionary)是一种映射类型,它不同于列表(list)这样的序列类型,它不是以偏移来存取,而是以键来存储,所以字典不支持切片这样的列表操作。
键的类型可以是数字,字符串,不包含可变对象的元组,不能使列表。字典可以被看做一个无序的集合。
常见操作:
1.新建字典;2.添加(键,值)对;3删除(键,值)对;4.由键查找对应的值;5.键,值上循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | >>> tel = {'jack': 4098, 'sape': 4139}>>> tel['guido'] = 4127>>> tel{'sape': 4139, 'guido': 4127, 'jack': 4098}>>> tel['jack']4098>>> del tel['sape']>>> tel['irv'] = 4127>>> tel{'guido': 4127, 'irv': 4127, 'jack': 4098}>>> tel.keys()['guido', 'irv', 'jack']>>> 'guido' in telTrue |
注意问题:序列运算无效;对新键赋值会创建新的项;键值的类型可以不同;避免keyError。
2.为什么列表不能做键
python使用开放散列数据结构实现的。不管是用列表的id还是用列表的内容用来散列,都是符合散列函数的定义的(不同的散列值,不同的键值)。但是这两种方式都存在一些问题:
- 用id散列时,在用不同的键值(id不同),但是内容相同的列表查找时,尽管散列值不同,但是在用列表却相同(满足__equal__)。此外,还有就是列表时一个容器,如果用id散列,意义到底有多大呢?
- 用列表内容散列时,列表内容该更改后,我们会计算出不同的散列值,就会有不同的bucket。
总之,在python中,选择了列表不能做键的策略。我感觉就是既然tuple类型可以用内容来散列,那么我们就不用列表了,列表修改特性会使散列的维护变得很复杂(想想如果我们使用列表的内容散列了,而后我们修改了,我们自己都不知道以前是什么了?如果想要保存以前的内容,不是又做了copy,这样就不如直接用tuple类型了),从而使得这种常用的数据类型的性能出现问题。
注意:用户自定义类型都可以用作键。只要用对象id散列,比较函数用id进行比较。为什么在列表中不可以,但是在自定义类型中就行?一个主要的原因就是对放在字典中的自定义类型来说,id重要,有了id就可以找到内容了。
#转帖#成为Python高手
本文是从 How to become a proficient Python programmer 这篇文章翻译而来。
- 函数式编程
- 性能
- 测试
- 编码规范