webdancer's Blog
c++笔记4
c/c++的数组与指针问题还是没有搞得太清楚,再仔细的研究一下。
指针:指向对象,存放对象的地址。
数组:一块连续的内存空间,静态初始化时确定数组的大小。
动态内存分配:在程序空间的动态内存区(堆)进行的空间分配。
赋值表达式:
LEFT = RIGHT
在赋值表达式,左右都能出现的成为左值。如:LEFT;只能出现在右边的称为右值。
在C语言里,又将左值分为了可修改与不可修改的左值。例如:数组名,就是个不可修改的左值。
int a[4]={1,2,3,4};
int *pa=a;
这样,pa与a都可以来引用数组里面的元素了,但是a与pa还是有区别的:pa可以作为可修改的左值,用来指向其他的对象,但是a是一个不可修改的左值,不能指向其他的对象。
数组名和指针的区别就是:数组名作为一个符号,在编译时是可知的,可以直接取到a的值。而指针作为变量,必须首先取得指针的值,然后得到地址。
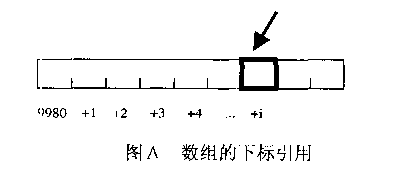
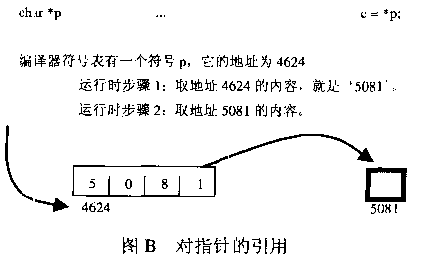
通常,定义指针:
int *p = 0; // 或int *p = NULL; int *p = new int;//C中用:int *p = (int *)malloc(sizeof(int));
二维数组的问题:
在c/c++里没有所谓的真正的二维数组,只有数组的数组,就是数组的元素还是数组,也是连续分配的空间。
例如:
int a[4][4];
int main(){
int i=0;
cout<<a[i]<<endl;
cout<<&(a[i])<<endl;
cout<<a+i<<endl;
cout<<*(a+i)<<endl;
cout<<*(a[i])<<endl;
char c;
cin>>c;
}
运行的结果为:
00A88138
00A88138
00A88138
00A88138
0
分别的意思是:
a[i]:第i行第0列地址。
&a[i]:第i行行首的地址。
a+i:第i行行首的地址。
*(a+i):第i行第0列地址。// *(a+i)+j与a+i+j 就有了明显的区别。
可以看出通过*(a+i)的行地址转为列地址,这样可以继续访问列里的元素。为什么:*(a[i])的值为:0,不明白??
怎么申请动态的二维数组:
c语言:
int **pp=0, i; pp = (int **)malloc(sizeof(int*)*row); for (i=0; i<row; i++) pp[i] = (int *)malloc(sizeof(int)*colum);
c++语言:
int **pp=new int* [row];
for(int i=0;i<row;++i){
pp[i]=new int[colum];
}
当然,指针的理解还得靠以后的逐渐积累,例如在函数参数的传值的应用,函数指针,太强大,真是有点晕。参考了很多人的东西,表示感谢。


c++学习笔记3
学习C++表达式时首先就是表达式,常见到的算术,关系,逻辑,赋值,条件,逗号等与C的一致,而且比较熟悉。主要是了解一下位操作,自增、自减,箭头,sizeof等。
1。位操作:~(求反),<<(左移),>>(右移),&(位与),^(为异或),|(位或)。可以对整型值进行运算,但是最好是对无符号整型的运算。其实,位运算的语法并不难,难得是二进制运算,必须按位运算,对各种类型必须十分熟悉。其实,用c++自带的bitset 类更简单,容易。
.2。自增(自减)运算:记住两点:
》后置操作符返回未加1时的值。
》前置操作符返回加1后的值,即对象本身。
vector<int> a(4,1); vector<int>::iterator iter=a.begin(); while(iter!=a.end()) cout<<*iter++<<endl
注意:*iter++:等价于:*(iter++),由于为后置++,所以解引用的是未加1之前的值。
.3。箭头(->):为指针类型的变量来取得属性。
4。sizeof : 返回一个类型或对象的长度,返回类型为:size_t。特别的:
》&类型是为返回对象的长度。
》*类型返回指针类型的长度。
》数组返回数组长度乘以数组类型的长度。
复合表达式的问题:
优先级,结合性真的不好记,真的需要的时候就查表吧!(ps:最近学编译,才知道什么叫烦。。必须仔细搞懂)。此外,注意求值顺序的问题。这是个很有趣的问题,
int a[2]={1,2};
int i=0;
if(a[i++]<a[i])
cout<<"a[0]<a[1]"<<endl;
如果左边先计算,a[0]<a[1],则会输出;如果右边先计算,a[0]<a[0],则不会输出。在我的机子里,不会输出。
new和delete的问题:
int *i=new int(6); cout<<*i<<endl;//1 delete i; i=0; cout<<*i<<endl;//2
delete以后,例如delete i 后,i变成了悬浮指针,此时可使用此指针。最好立即将此指针赋值为0。然后,使用此指针会有异常出现。上面的例子中:第二次cout会出现异常。不同的编译器处理也不同,在vc中,上面的例子无法运行;在gcc中可以运行。在动态内存管理中,经常造成内存管理错误,比如删除指针错误,读取删除的对象。
类型转换:
隐式类型转换可能要理解一下,经常用,但是以前不太明白。
string s; while(cin>>s)
不知道测试的什么,在这里会做类型转换。
浏览器使用的启示
现在的浏览器很多,但是主流的主要是IE,Firefox,Chrome等。
自从,Chrome问世后,他就一直在引领着浏览器的方向,现在各个浏览器用户界面都在模仿Chrome。Chrome关注了用户的需求,提供了最基础的服务:简洁的界面,快速的浏览速度,兼容性。作为一个普通的用户,几乎很少去设置浏览器,所以,像Word那样有很多的工具标签,其实用处很少的。Chrome的简单风格,快速的加载速度让用户很爽。记得刚开始用的时候,兼容性不好,但是现在感觉很好,而且能同步书签,扩展插件,定制皮肤,我关注的几个方面都满足了。除此之外,Chrome在Windows和Linux下用户界面的高度一致,让我感觉很好。所以,在Ubuntu和windows7下可以体验完全相同的操作,根本没有平台的差异。所以,Chrome几乎是我的首选。
Firefox是我除IE外接触的第一款浏览器,但是,与Chrome对比,我体验不到更多的好处,缓慢的启动速度让人诟病,网银等支持也并不友好,也许,大量的第三方插件要比Chrome稳定一些。当然,FF还是一款非常好的浏览器。
如果你没有体验过Chrome的速度,你也许不会知道IE是多么的慢和笨拙,微软对浏览器的漠视让他自食其果。现在,微软开始重视了,IE9的速度相比IE8进步很大,可以让你很明显的感觉出来,在我的系统里IE8真的很慢。而IE9的速度已经感觉不出与Chrome的差距了,但是,我的体验是:输入网址后,有明显的延迟,然后才出网页。希望IE能越来越好。
作为,互联网巨头的google显然比微软提前明白了浏览器的真谛:界面,速度,兼容性。在这里的兼容性应该是正规的web标准。当然,微软也不能自甘落后,开始优化IE了,添加了很多功能。如果,微软的速度再更快一些,那么Chrome危险了。跟Windows的绑定依然是微软的必杀技。当然,微软的行动缓慢,是大家都知道的了。所以Chrome还是大有希望。
从中可以体会的是:必须好好地理解用户需求,进行创新,简单就是美。而且,及时的跟踪对手也是必须的,落后了就很难追了。微软IE还会往下跌吗?
浏览器份额(2010.9):

浏览器份额(2009.9)

python学习
python是一种脚本语言,不用经过编译。这是我学习的第一种不用经过编译的高级语言。python有很多的分支,通常的python 解释器是用c 实现的。
启动python的方式,通常有三种,(1)命令行交互;(2)脚本;(3)GUI图形界面。我在linux下面学习,所以选择第一种。
命令选项:可以通过man python 來查询。下面是通常用到的:
-d: 提供调试输出。
-O:生成优化的字节码
-S :不导入site模块。
-v :冗余输出。
-m mod :将某一模块以脚本方式运行。
file :从脚本文件运行。
基本要素:
1) 输出: print ; 可以格式化输出。 2)输入 :内置函数:raw_input(“提示内容”);
2)运算符:算术运算:+,-,*,/,%,//,**;
关系运算:>,<=,<,>=,==,!=,<>;
逻辑运算:and , or ,not.
注:通常使用help()可以查询函数功能。
3)变量:动态语言,使用前不必声明。
4)字符串:[]:索引;+:连接;*:重复。
5)缩进:代码中用缩进来表示块,而不是大括号.
结构语句:条件,循环的结构。
条件:
if expression1:
if_suite
elif expression2:
elif_suite
else:
else_suite
循环:
while expression:
while_suite
for item in List
do_for
函数:
def Function_name([arguments]):
'may have some clairation'
functionblock
类定义:
class ClassName(base_class[es]):
"optional documentation string"
static_member_declarations
method_declarations
模块:
模块是一种组织形式, 它将彼此有关系的 Python 代码组织到一个个独立文件当中。
模块可以包含可执行代码, 函数和类或者这些东西的组合。
import 模块名
文件:
打开文件:FileHanle=open(File_path,acessMode);
et:
filename = raw_input('Enter file name: ')
fobj = open(filename, 'r')
for eachLine in fobj:
print eachLine,
fobj.close()
异常处理:
try:
code_block
except EXCEPTION, e:
exception_code
感觉:python与我以前学的语言真得不同,没了大括号,但要加:,还要注意缩进。但是,也很简单比较容易。
书上给的几个函数:
dir([obj])
显示对象的属性,如果没有提供参数, 则显示全局变量的名字
help([obj])
以一种整齐美观的形式 显示对象的文档字符串, 如果没有提供任何参数, 则会进入交互式帮助。
int(obj)
将一个对象转换为整数
len(obj)
返回对象的长度
open(fn, mode) 以 mode('r' = 读, 'w'= 写)方式打开一个文件名为 fn 的文件
range([[start,]stop[,step])
返回一个整数列表。起始值为 start, 结束值为 stop - 1; start
默认值为 0, step默认值为1。
raw_input(str) 等待用户输入一个字符串, 可以提供一个可选的参数 str 用作提示信息。
str(obj)
将一个对象转换为字符串
type(obj)
返回对象的类型(返回值本身是一个 type 对象!)
Pythonic八荣八耻
以打印日志为荣 , 以单步跟踪为耻;
以空格缩进为荣 , 以制表缩进为耻;
以单元测试为荣 , 以人工测试为耻;
以模块复用为荣 , 以复制粘贴为耻;
以多态应用为荣 , 以分支判断为耻;
以Pythonic为荣 , 以冗余拖沓为耻;
以总结分享为荣 , 以跪求其解为耻;
c++笔记2
现在才觉得当自学的时候,应该看一本好书。先到网上搜一下,再下决定。记得当时学C的时候,看的那本书并没有把C的特点给说明白,对指针也是很含糊。现在看着本书,真的很好。
1.数组初始化。
如果没有显式的初始化:
》在函数体外定义的内置数组,会进行初始化:0。
》在函数体内定义的内置数组,不进行初始化。
》类类型,不论定义在何处,都自动调用默认构造函数。若没有默认的构造函数,则必须显式的初始化。
2.数组不能直接赋值,而且一定要保证下标的范围。说起来简单,我就经常犯错误。
3.const与*。
我以为理解的可以了,一个例子又把我搞晕了。
string s1="hello";
string s2="world";
typedef string * pstr;
const pstr str=&s1;
*str="world";
cout<<*str<<endl;
正常编译,不会出错。原来理解成了:const string * str。关键把typedef的作用理解错了,认为成文本替换了。正确的是:
string * const str。
ps: The typedef keyword allows you to create a new alias for an existing data type.
4.减少c风格string的使用。主要是:减少错误。
c++学习笔记
其实,以前是自学过C++的,但是,感觉很挫。于是,又看《c++ primer》。觉得,这本书解释的很清楚,而且,很多提醒的地方,很好。就记录 一下。
(1)声明和定义。
变量的定义为变量分配存储的空间,还可以初始化。在一个程序中,变量只能定义一次。
变量的声明用于向程序说明变量的类型和名字。定义也是声明。可以 用extern来声明而不定义。
(2)const限定符。
容易混淆的原因是:c中的const与c++的const完全不同,在c中的const只是readonly的意思,并不是真正的常量定义符号,只是不能被赋值,但是,不能保证不被修改。而在C++中,const就是定义常量,而且是定义在该文件上的局部变量。
const 修饰指针符号*,位置不同时意义不同,这都是由于c语言声明的复杂性。 《c专家编程》有总结。
(3)头文件。
在头文件中,不应该含有变量或是函数的定义,但是可以定义类,const对象,inline函数。
(4)string.
标准库定义的string类型字符串,与字符串字面量不是同一类型。例如:两个字符串字面量不能用+来连接,但是string类型变量就可以。
vim使用
由于最近重装了Ubuntu,所以得重新配置vim,由于以前也没怎么好好的学vim,所以我觉得还是很有必要学习一下的。最近看了一下《unix技术手册》,文本编辑有足足的一篇,可以看到文本编辑的重要性。作为程序员或是系统管理员,熟练使用文本编辑软件是必需的。所以,决定再好好的学习一下!
vim的用途就是文本编辑,它能高效的完成文本编辑工作。一般而言,vim编辑的都是无格式的文本,当然与其他的工具结合,可以做出我们我们想要的效果,比如:vim-latex可以高效编辑tex文件。
1. vim的配置
主要解决以下几个问题,语法高亮,缩进,编码,显示行号等。
- 语法高亮,默认开启
- 缩进
set tabstop=4 set softtabstop=4 set shiftwidth=4 set autoindent
3.编码
set enc=utf-8 set fencs=utf-8,ucs-bom,shift-jis,gb18030,gbk,gb2312,cp936
4.显示行号
set nu
当然,vim可以配置的相当的非常强大。
2. vim命令
vim有三种模式:正常模式,插入模式和视图模式。在正常模式下,可以执行命令。
- 移动命令
| 命令 | 作用 |
| h | 左移光标一个字符(行内移动) |
| l | 右移光标一个字符(行内移动) |
| k | 光标上移一行(行间移动) |
| j | 光标下移一行(行间移动) |
| ^/0 | 光标移动至行首(行内移动) |
| $ | 光标移动至行尾(行内移动) |
| gg | 光标移至文章的开头(行间移动) |
| G | 光标移至文章的最后 |
注意:h,l,k,j前面可以加数字d,表示行内移动的距离d;
gg,G前面加数字n表示跳转到第n行;
*号可以快速定位光标指向的单词
2.滚屏
| 命令 | 作用 |
| Ctrl+f | 向前翻屏 |
| Ctrl+b | 向后翻屏 |
| Ctrl+d | 向前翻半屏 |
| Ctrl+u | 向后翻半屏 |
注意:翻屏在我们用vim阅读时比较有用
3.编辑
| 命令 | 作用 |
| i | 在光标位置前插入字符 |
| a | 在光标所在位置的后一个字符开始增加 |
| o | 插入新的一行,从行首开始输入 |
| 命令 | 作用 |
| i | 在光标位置前插入字符 |
| a | 在光标所在位置的后一个字符开始增加 |
| o | 插入新的一行,从行首开始输入 |
| x | 删除光标后面的字符 |
| dd | 删除光标所在的行 |
| yy | 复制光标所在位置的一行 |
| p | 粘贴 |
| u | 取消操作 |
| cw | 更改光标所在位置的一个字 |
4. 其他有用的命令
| 命令 | 作用 |
| :w filename | 储存正在编辑的文件为filename |
| :wq filename | 储存正在编辑的文件为filename,并退出 |
| :q! | 放弃所有修改,退出 |
| :set nu | 显示行号 |
| /或? | 查找,在/后或?前输入要查找的内容 |
| * | 快速定位光标指向的单词 |
| n | 与/或?一起使用,如果查找的内容不是想要找的关键字,按n或向后(与/联用)或向前(与?联用)继续查找,直到找到为止。 |
3. 学会使用vim帮助文档
vim的帮助文档写的非常好,在遇到问题时,首先想到的就是查找帮助。
shell排序算法
shell排序算法是一种插入排序算法,直接的插入算法很简单,shell算法不同于直接插入的插入时小步挪动,而做长距离的跳动。它由Donald Shell于1959年提出。
shell算法也叫作“减少增量的排序算法”,每一遍通过增量h,使得那些相距h的记录排序。增量的序列不是固定的,确定最好的增量序列需要大量的数学知识。
shell算法:
<1>确定增量序列S[ t]。
<2>对给出的记录,按照增量序列S,进行t遍排序。
<3>对每遍进行直接插入。
/*为了编程方便,增量序列采用:
[n/2,n/4,......,1].实际的增量序列很是有趣。
*/
void shsort(int a[],int n){
int i,j;
for(i=n/2;i>=1;i/=2){
for(j=i;j<n;j++){
int k;
for(k=j-i;k>=0&&a[k]>a[k+i];k-=i){
int t=a[k];
a[k]=a[k+i];
a[k+i]=t;
}
}
}
}
我觉得还是挺有趣的,注意算法在利用直接插入时的方法,后面的元素不断的插入。