webdancer's Blog
排序算法
我的算法可以说应该是很烂,归结起来:(1)不善总结,无法融汇贯通,与性格有关。(2)经常忘记,无法应用的好,与智商有关。我觉得:智商不高,还可以在计算机世界里混,但是若是性格不好,不能坚持,我觉得难有成绩。现在,该录正题了。
排序到底有什么用呢?对于我来说,我以前没有认真思考过这个问题,在Tao里,作者总结了一下,这里记录一下:
(1)解决“一起性”问题,把具有相同标志的项目连在一起。其实,sort在英文中就有 分类 的意思。把相同的东西归到一起,排序实在是好呀!
(2)匹配在两个文件或更多的文件中的项。 排好序就可以顺序的扫描,而不用跳来跳去。
(3)通过键码查询信息。很多的检索算法用得到排序,向我们熟悉的二分查找,不就是对已经排好序的序列。
排序分为:内部排序和外部排序。所有的数据都可以放入主存中时,采用内部排序;当不能完全的放入主区,则只能采用外部排序。我还是先学习一下内部排序。
(1)直接插入排序。这种排序思想简单,就是在已经排好序的序列中,插入元素。
/*直接插入*/
void chsort(int a[],int n){
int j,k;
for(j=1;j<n;j++){
k=a[j];
int i=j-1;
while(a[i]>k){
a[i+1]=a[i];
i--;
}
a[i+1]=k;
}
}
(2)通过交换排序。
冒泡排序:
/*冒泡排序*/
void bsort(int a[],int n){
int isch=1 , i,j;
for(i=n-1;i>0&&isch;i--){
isch=0;
for(j=0;j<=i;j++){
if(a[j]>a[j+1]){
int t;
t=a[j];
a[j]=a[j+1];
a[j+1]=t;
isch=1;
}
}
}
}
快速排序:
/*快速排序的划分方式,a[r] 有最大的值。*/
void sortone(int a[],int l,int r){
if(l>=r) return;
int i=l+1,j=r;
int base=a[l];
while(i<j){
while(a[i]<base)
i++;
while(a[j]>base)
j--;
if(i<j){
int t=a[i];
a[i]=a[j];
a[j]=t;
}
}
a[l]=a[j];
a[j]=base;
/*递归的调用sortone*/
sortone(a,l,j-1);// First, the wrong is: sortone(a,l,j).
sortone(a,j+1,r);
}
/*为了排序的接口统一*/
void qusort(int a[],int n){
sortone(a,0,n-1);
}
快速排序分析:
//使用快排对a[0...n-1]进行排序。
从a[0...n-1]中选择支点,把剩下的分为两段:left ,right;左边的都小于支点,右边的都大于支点。然后,递归的来对left,right进行排序,最后的结果为:left ,支点,right。
如何选择支点进行划分left,right会严重的影响快排的效率,我选择了教科书上的给出支点a[0]。但是,不是很好呀! 快排对已经有序的序列进行排序,时间复杂度会上升的O(n2),偏爱无序的序列。
不知道C函数库中的:
void qsort( void *buf, size_t num, size_t size, int (*compare)(const void *, const void *) );
如何实现的。
(3)选择排序。
/*直接选择排序*/
void xzsort(int a[],int n){
int j;
for(j=n-1;j>0;j--){
int maxIndex=0,i;
for(i=1;i<=j;i++)
if(a[i]>a[maxIndex])
maxIndex=i;
int t;
t=a[maxIndex];
a[maxIndex]=a[j];
a[j]=t;
}
}
利用MAXHEAP来实现选择排序应该是一种很好的方法。MaxHeap数据结构的构建还是比较复杂的,涉及到构建堆,插入,删除MAX等。感觉在构建复杂的数据类型时,c++/java等引入了类的语言还是简单呀!
有限自动机(DFA)分析
DFA可以用状态表来形象的表示,如下:
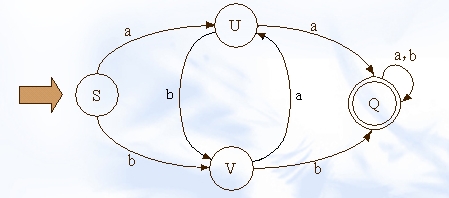
(图摘自http://www.javaeye.com/topic/336577,文章讲述了如何利用dfa来进行文字过滤)
它有点和边构成,其中点成为状态;边称为转移。状态中两种状态较为特殊:初始状态(s)和接受状态(Q)。
DFA精确定义:
DFA是一个 (Q,Σ ,§, q0,F) 构成的五元组,其中:
1.Q是有限状态集合。2.Σ 是有限字符集合。3.§是(Q,Σ )—>Q的转移函数。4。q0是初始状态。5.F是接受状态集合。
注:能被确定有限状态自动机识别的语言是正则语言。
DFA运算的精确定义:
设M= (Q,Σ ,§, q0,F)是一个DFA,w=w1w2w3...wn是一个language.那么,如果存在状态序列r0r1r2...rn,且满足以下三个条件:
(1)r0=q0;(2)§(ri , wi )=r(i+1) ,i=0,1,2,3,...,n (3) rn=F。
则称M接受w。
如何设计自动机:
设计自动机应该是极富创造力的工作,但是还是应该掌握一些构造的技巧:
(1)当你读字符串时,搞清楚应该记住关于字符串的什么信息。提取一些关键信息,确定可能性,得出状态集Q。
(2)通过转移来得到状态序列。
(3)确定初始、接受状态。
当然,以上只是简单的描述。
如何来描述DFA呢?
使用什么样的数据结构来描述DFA呢?
(1)根据状态图,当然可以使用矩阵来表示。
(2)也可以用Trie树来表示。可以,使用DAT。
UNIX v6 的fork系统调用实现分析
最近一直在阅读《莱昂氏unix代码分析》,硬件的基础有点差,PDP11结构也是不太清楚,汇编语言也不行。有很多的疑问,现在还是看一看unix v6 中的fork系统调用如何实现的呢?
/*
*/
#include "../param.h"
#include "../user.h"
#include "../proc.h"
#include "../text.h"
#include "../systm.h"
#include "../file.h"
#include "../inode.h"
#include "../buf.h"
/* -------------------------
*/
/*
* Create a new process-- the internal version of
* sys fork.
* It returns 1 in the new process.
* How this happens is rather hard to understand.
* The essential fact is that the new process is created
* in such a way that it appears to have started executing
* in the same call to newproc as the parent;
* but in fact the code that runs is that of swtch.
* The subtle implication of the return value of swtch
* (see above) is that this is the value that newproc’s
* caller in the new process sees.
*/
newproc()//无参数
{
int a1, a2;
struct proc *p, *up;
register struct proc *rpp;
register *rip, n;
p = NULL;
/*
* First, just locate a slot for a process
* and copy the useful info from this process into it.//为新建的进程寻找存储槽,并复制有用的信息。
* The panic "cannot happen" because fork already
* checked for the existence of a slot.
*/
retry:
mpid++;//mpid,整形值,0-32767之间递增,用作进程号。
if(mpid < 0) {
mpid = 0;
goto retry;
}
for(rpp = &proc[0]; rpp < &proc[NPROC]; rpp++) {//在proc数组中,寻找空元素。
if(rpp->p_stat == NULL && p==NULL)//由p_stat来判断,是否为空。
p = rpp;
if (rpp->p_pid==mpid)
goto retry;
}
if ((rpp = p)==NULL)
panic("no procs");
/*
* make proc entry for new proc
*/
rip = u.u_procp;//当前进程proc项的地址。
up = rip;
rpp->p_stat = SRUN;
rpp->p_flag = SLOAD;
rpp->p_uid = rip->p_uid;
rpp->p_ttyp = rip->p_ttyp;
rpp->p_nice = rip->p_nice;
rpp->p_textp = rip->p_textp;
rpp->p_pid = mpid;
rpp->p_ppid = rip->p_ppid;
rpp->p_time = 0;
/*
* make duplicate entries
* where needed//复制打开文件。
*/
for(rip = &u.u_ofile[0]; rip < &u.u_ofile[NOFILE];)
if((rpp = *rip++) != NULL)
rpp->f_count++;
if((rpp=up->p_textp) != NULL) {
rpp->x_count++;
rpp->x_ccount++;
}
u.u_cdir->i_count++;
/*
* Partially simulate the environment
* of the new process so that when it is actually
* created (by copying) it will look right.
*/
savu(u.u_rsav);//保存环境和栈指针。
rpp = p;
u.u_procp = rpp;
rip = up;
n = rip->p_size;
a1 = rip->p_addr;
rpp->p_size = n;
a2 = malloc(coremap, n);//申请内存。
/*
* If there is not enough core for the
* new process, swap put the current process to
* generate the copy.
*/
if(a2 == NULL) {//申请不到内存。
rip->p_stat = SIDL;
rpp->p_addr = a1;
savu(u.u_ssav);
xswap(rpp, 0, 0);
rpp->p_flag =| SSWAP;
rip->p_stat = SRUN;
} else {
/*
* There is core, so just copy.
*/
rpp->p_addr = a2;
while(n--)
copyseg(a1++, a2++);
}
u.u_procp = rip;
return(0);
}
总结一下过程:
1.首先,应该为进程取得一个惟一的进程号。
2.将当前进程的proc复制到新进程的proc结构。
3.将当前进程的打开文件复制到新进程,同时增加文件引用。
4.进行内存分配,如果内存不足,则放入交换区,否则,分配内存。
UNIX的proc数组,当前LINUX是一个task_struct 结构的双向链表,结构更加复杂。但是,实现的基本思想应该变化不大。
阅读《莱昂氏UNIX源代码分析》
malloc.c源代码:
/*
* Structure of the coremap and swapmap %两类资源:主存(64B); 盘交换区(512B)。
* arrays. Consists of non-zero count %coremap swapmap 维护可用资源的列表。
* and base address of that many %资源类别都包含连续的单元(map)。 如此下面
* contiguous units. %malloc函数可以连续的查找。
* (The coremap unit is 64 bytes,
* the swapmap unit is 512 bytes)
* The addresses are increasing and %可用资源列表结束的标志就是map类型单元为0.
* the list is terminated with the
* first zero count.
*/
struct map
{
char *m_size; //map结构的大小
char *m_addr; //map结构的地址
};
/* -------------------------
*/
/*
* Allocate size units from the given
* map. Return the base of the allocated
* space.
* Algorithm is first fit.
*/
malloc(mp, size)
struct map *mp;
{
register int a;
register struct map *bp;
for (bp = mp; bp->m_size; bp++) { //bp->m_size等价于:bp->m_size>0; bp++:列表为连续的。
if (bp->m_size >= size) { //找到要用的区域,由于算法采用的为:first fit.
a = bp->m_addr; //记录该区域的首单元地址,作为返回的地址。
bp->m_addr =+ size;//更改该区域的首单元地址
if ((bp->m_size =- size) == 0)//减少长度,判断是否恰好适配,恰好适配时,资源列表资源数减少。
do {
bp++;
(bp-1)->m_addr = bp->m_addr;//后续元素下移。
} while((bp-1)->m_size = bp->m_size); //判断(bp-1)->m_size是否为0
return(a);//返回该区域的地址
}
}
return(0);//返回0,没找到区域。
}
/*----------------------
*/
/*
* Free the previously allocated space aa
* of size units into the specified map.
* Sort aa into map and combine on
* one or both ends if possible.
*/
mfree(mp, size, aa) //将资源返回给mp指定的资源图。
struct map *mp;
{
register struct map *bp;
register int t;
register int a;
a = aa;
for (bp = mp; bp->m_addr<=a && bp->m_size!=0; bp++);//为了寻找释放资源在资源图中的位置。
if (bp>mp && (bp-1)->m_addr+(bp-1)->m_size == a) {//寻到在它之前插入新元素的元素。是否合并
(bp-1)->m_size =+ size;
if (a+size == bp->m_addr) {//是否应该与下一元素合并
(bp-1)->m_size =+ bp->m_size;
while (bp->m_size) {//元素数减1,位置前移。
bp++;
(bp-1)->m_addr = bp->m_addr;
(bp-1)->m_size = bp->m_size;
}
}
} else {//不能并于列表中的前一元素。
if (a+size == bp->m_addr && bp->m_size) {//是否与后一元素合并
bp->m_addr =- size;
bp->m_size =+ size;
} else if(size) do {//既不能与前面的&&后面的合并,在列表中增加元素。逐一后移。
t = bp->m_addr;
bp->m_addr = a;
a = t;
t = bp->m_size;
bp->m_size = size;
bp++;
} while (size = t);
}
}
/*-----------------------
*/
/*
算法分析:
在《os 概念》中,内存的分配介绍了三种方法:连续,分页,分段。 UNIX v6 是基于pdp11,上面的内存分析显然是简单的连续分配,对pdp11不太了解,不知道为什么用此类方式。采用动态分配的方式,可能含有外部碎片。使用了first fit 算法。这个算法的明显特点(就目前我所知)是搜索的速度快,可快速找到。
malloc :算法就是在资源可用图中连续找到可用元素,采用first fit.
free :将该内存释放在指定的区域,需要仔细的考虑合并的问题。
疑惑:
对malloc函数的连续查找还是不太明白,资源分配图好像可以不连续呀?
Makefile知识
Makefile包含5种内容:显式规则,隐含规则,变量定义,Makefile指示符(指示符指明在 make 程序读取 makefile 文件过程中所要执行的一个动作。),注释。
Makefile文件的名称默认顺序为:GNUmakefile,makefile,Makefile。 (gnu 文档中推荐使用 Makefile,因为大写开头更靠近一些重要文件,如README)。如果不采用以上的默认名称:可以采用"-f filename" 或者"--file=filename" 参数来指定Makefile文件。
1.包含其他的Makefile文件,可以采用include指示符,但是不能以<Tab>开头,可以有空格。
使用情况:
make 程序在处理指示符 include 时,将暂停对当前使用指示符“include”的 makefile 文件的读取,而转去依此读取由“include”指示符指定的文件列表。直到完成所有这些文件以后再回过头继续读取指示符“include”所在的 makefile文件。
2.有些情况下,存在两个比较类似的 makefile 文件。其中一个(makefile-A)需要使用另外一个(makefile-B)中所定义的变量和规则。但是,两个文件有一些目标文件相同,为避免同意目标文件有两种或以上的规则产生,可采用一下方法。
看一个例子,如果存在一个命名为“Makefile”的makefile 文件, 其中描述目标“foo”的规则和其他的一些规,我们也可以书写一个内容如下命名为“GNUmakefile”的文件。
foo:
frobnicate > foo
%: force
@$(MAKE) -f Makefile $@
force: ;
注:(1).$(MAKE)是内置变量,可以通过make -p 查看。MAKE = $(MAKE_COMMAND) MAKE_COMMAND := make。可以知道$(MAKE) :=make 。
(2).规则之前加@,本命令行不显示。
例如:make foo 命令时,使用frobnicate > foo ,可是make bar 命令时,则采用模式规则,使用@MAKE -f Makefile $@,如果Makefile中,有bar 的规则,则可使用。
3.变量:
在gnu make中,有两种不同的变量定义风格,主要有2点不同:(1)定义方式;(2)展开时机。
(1)递归展开变量:采用方式 VALUENAME = value
(2)直接展开变量:采用方式 VALUENAME := value
尽量使用(2)种方式,第一种问题较多。
变量的追加: 使用+=符号。
注意:1. 如果被追加值的变量之前没有定义,那么,“+=”会自动变成“=”,此变量就被定义为一个递归展开式的变量。如果之前存在这个变量定义,那么“+=”就继承之前定义时的变量风格。
2. 直接展开式变量的追加过程:变量使用“:=”定义,之后“+=”操作将会首先替换展开之前此变量的值,尔后在末尾添加需要追加的值,并使用“:=”重新给此变量赋值。
4.条件执行:
条件语句 用于控制 make 实际执行的 makefile 文件部分,它不能控制规则的 shell 命令执行过程。Makefile 中使用条件控制可以做到处理的灵活性和高效性。
语法规则:
conditional-directive
text-if-one-is-true
else conditional-directive
text-if-true
else
text-if-false
endif
条件判断有四种:
1.ifeq
ifeq (arg1, arg2)
ifeq 'arg1' 'arg2'
ifeq "arg1" "arg2"
ifeq "arg1" 'arg2'
ifeq 'arg1' "arg2"
2.ifneq.方式同上。
3.ifdef.
ifdef variable-name
4.ifndef.
ifndef variable-name
ifdef 只是测试一个变量是否有值,不会对变量进行替 换 展 开 来 判 断 变 量 的 值 是 否 为 空 。
Makefile文件的书写
学习分析源代码,和自己在Linux底下Makefile文件的书写很重要。但是,这是一个逐渐积累的过程,先学一下基本的吧!
Makefile的语法较为复杂,可以参考GNU的官网。http://www.gnu.org/software/make/manual/make.html
1.make命令不仅使用在编译类型的程序文件,还是用于有几个输入文件产生输出文件的情况;比如是文档处理。
2.Makefile语法:
一个Makefile文件包含:依赖关系和规则. 一条依赖关系包含目标文件和它所依赖的源文件.规则:描述了如何由源文件产生目标文件。
目标文件: 源文件1 源文件2 [...]
<tab> 规则 #(注:此处必须是tab键打头)。
(1.)依赖关系:
目标文件产生所依赖的源文件,两者用:与空格分开;格式为:
目标文件: 源文件1 源文件2 […]
例如:
all: main.o 1.o 2.o
main.o: main.c a.h
1.o: 1.c a.h
2.o: 2.c b.h
注意: 在gcc 编译器中有 -MM选项,它可以产生依赖关系。所以,把它产生的输出到某个文件就可以了。
(2)规则:
产生目标文件的语法,可以使用gcc 命令。格式为:
<tab> rules
3.#为注释。从行首到行末。
4.Makefile文件里的宏。
MACRONAME=VALUE
使用时${MACRONAME} 或者 $(MACRONAME)
宏经常用在编译器的选项上。
在make执行shell命令时,每一条命令会打开一个shell,所以加\來连接。
自定义变量:
AR 库文件维护程序的名称,默认值为 ar
AS 汇编程序的名称,默认值为 as
CC C 编译器的名称,默认值为 cc
CPP C 预编译器的名称,默认值为$(CC) –E
CXX C++编译器的名称,默认值为 g++
FC FORTRAN 编译器的名称,默认值为 f77
RM 文件删除程序的名称,默认值为 rm –f
ARFLAGS 库文件维护程序的选项,无默认值
ASFLAGS 汇编程序的选项,无默认值
CFLAGS C 编译器的选项,无默认值
CPPFLAGS C 预编译的选项,无默认值
CXXFLAGS C++编译器的选项,无默认值
FFLAGS FORTRAN 编译器的选项,无默认值
自动变量:
$* : 不包含扩展名的目标文件名称。
$+ : 所有的依赖文件,以空格分开,并以出现的先后为序,可能包含重复的依赖文件。
$< : 第一个依赖文件的名称 。
$? : 所有时间戳比目标文件晚的依赖文件,并以空格分开
$@: 目标文件的完整名称
$^ : 所有不重复的依赖文件,以空格分开
$% : 如果目标是归档成员,则该变量表示目标的归档成员名称
5。内建规则:
模式规则是用来定义相同处理规则的多个文件的。它不同于隐式规则,隐式规则仅仅能够用 make 默认的变量来进行操作,而模式规则还能引入用户自定义变量,为多个文件建立相同的规则,从而简化 Makefile 的编写。
模式规则的格式类似于普通规则,这个规则中的相关文件前必须用“%”标明。使用模 式规则修改后的 Makefile 的编写如下:
OBJS = kang.o yul.o
CC = Gcc
CFLAGS = -Wall -O -g
sunq : $(OBJS)
$(CC) $^ -o $@
%.o : %.c
$(CC) $(CFLAGS) -c $< -o $@
6.make 管理函数库:
函数库是一种目标文件的集合,后缀.a。make语法使得管理变得很简单,语法为:lib(file.o),可以把文件加入到函数库中。
7.make使用:
-C dir 读入指定目录下的 Makefile
-f file 读入当前目录下的 file 文件作为 Makefile
-i 忽略所有的命令执行错误
-I dir 指定被包含的 Makefile 所在目录
-n 只打印要执行的命令,但不执行这些命令
-p 显示 make 变量数据库和隐含规则
-s 在执行命令时不显示命令
-w 如果 make 在执行过程中改变目录,则打印当前目录名。
gcc使用--编译c++程序
gcc的c++编译器可以产生可执行的目标代码,而且其作为补充加入到gcc中的。直接使用gcc命令來编译c++程序,会出现错误。例如 程序1 exam.cc:
#include<iostream>
int main(int argc,char * argv[]){
std::cout<<"hello world"<<std::endl;
return 0;
}
命令1: gcc exam.cc (错误) 。程序编译错误,“ld returned 1 exit status“,无法编译通过。
命令2: gcc -lstdc++ exam.cc 。程序编译通过。-l:链接库文件。
命令3: g++ exam.cc 。程序编译通过。
g++ is a program that calls GCC and treats .c, .h and .i files as C++ source files instead of C source files unless -x is used, and automatically specifies linking against the C++ library.
(g++ 会自动调用GCC,而且会将.c,.h,.i作为c++源文件而不是c的源文件,除非-x 选项被使用,而且自动链接c++库.)。也就是将语言默认为c++了。
后缀:
头文件:C++文件的头文件较多,可以使用.hh, .hpp, .H, 或者.tcc。
源文件: .C, .cc, .cpp, .CPP, .c++, .cp, or .cxx。
汇编语言文件:.ii。
注意:
库文件:c++的库文件名为stdc++.a,包含几乎所有的c++例程。
其他的命令与前面GCC的简单使用的差不多。所以就不说了。当然,编译程序肯定会遇到各种的问题,一定要注意查资料。
GCC的简单使用
这学期要学操作系统的课程设计了,编译器的学习是必需的了。当然,由于平台基于Linux,所以学习GCC是必须的了。
GCC 是“GNU Compiler Collection” 的简称,而不是以前的 “GNU C Compiler “。它支持 c ,c++,object-c,objectc+,Fortran,Java和Ada。 GCC编译器的选项真的非常之多,通常可以分成三种:
1.平台相关的选项。所谓的平台,是指机器(主要是芯片)和OS。下表:
|
Hardware |
Operating System
|
|
PowerPC |
Linux
|
|
Sparc |
Linux
|
|
ARM |
Linux
|
|
Intel x86 |
Cygwin Linux
|
2.语言相关的选项。
3.一般性选项。
GCC的编译过程:
预处理、编译、汇编、链接;通过一定的gcc选项,可以使编译过程停留在某一阶段。例如:-C 可以阻止链接过程,只是产生目标文件。文件的后缀通常决定怎么编译。例如:
|
.a |
Static object library (archive). |
|
.c |
C source code that is to be preprocessed. |
|
.h |
C source code header file. |
|
.i |
C source code that is not to be preprocessed. This type of file is produced as an intermediate step in compilation. |
|
.o |
An object file in a format appropriate to be supplied to the linker. This type of file is produced as an intermediate step in compilation. |
|
.s |
Assembly language code. This type of file is produced as an intermediate step in compilation. |
集中常用的gcc命令:
(1)、单个源文件产生可执行文件。
命令:源文件:a.c
gcc a.c
结果:产生a.out 可执行文件。
(2)、产生目标文件。
命令:gcc -c a.c -o a.o
结果:产生a.o目标文件。
(3)、多个源文件产生可执行文件。
命令: gcc a.c b.c -o a
(4)、预处理。
命令: gcc -E a.c -o a.i
(5)、产生汇编文件。
命理: gcc -S a.c
(6)、创建静态库。
命令:gcc -c a.c b.c
ar -r liba.a a.o b.o
(7)、创建动态库。
命令:gcc -c -fpic a.c b.c
gcc -shared a.o b.o -o a.so
(8)、避免后缀转换。
命令: gcc -xc a.ccc (-x 后面跟具体的语言。)