webdancer's Blog
python科学计算——numpy
numpy是python进行科学计算的一个基础包,它的核心功能是提供ndarray对象,一个实现了n维数组的对象,与python自带的list相比,数组大小初始化时候确定,而且是单一类型(当然也可以使用 对象,这样也能包含多种对象),速度更快,大多数科学计算的程序可能都是基于numpy的。
1.基本的思想有两个:vectorization和broadcasting.
- vectorization:说的是可以不适用for,而像线性代数里面提供的操作一样进行计算;
- broadcasting:指的是对于element-by-element的计算,可以自动进行;
2.数据类型:支持丰富的数值类型,如下:
| Data type | Description |
|---|---|
| bool_ | Boolean (True or False) stored as a byte |
| int_ | Default integer type (same as C long; normally either int64 or int32) |
| intc | Identical to C int (normally int32 or int64) |
| intp | Integer used for indexing (same as C ssize_t; normally either int32 or int64) |
| int8 | Byte (-128 to 127) |
| int16 | Integer (-32768 to 32767) |
| int32 | Integer (-2147483648 to 2147483647) |
| int64 | Integer (-9223372036854775808 to 9223372036854775807) |
| uint8 | Unsigned integer (0 to 255) |
| uint16 | Unsigned integer (0 to 65535) |
| uint32 | Unsigned integer (0 to 4294967295) |
| uint64 | Unsigned integer (0 to 18446744073709551615) |
| float_ | Shorthand for float64. |
| float16 | Half precision float: sign bit, 5 bits exponent, 10 bits mantissa |
| float32 | Single precision float: sign bit, 8 bits exponent, 23 bits mantissa |
| float64 | Double precision float: sign bit, 11 bits exponent, 52 bits mantissa |
| complex_ | Shorthand for complex128. |
| complex64 | Complex number, represented by two 32-bit floats (real and imaginary components) |
| complex128 | Complex number, represented by two 64-bit floats (real and imaginary components) |
3.创建数组:有5中基本的方式:
- Conversion from other Python structures (e.g., lists, tuples)
- Intrinsic numpy array array creation objects (e.g., arange, ones, zeros, etc.)
- Reading arrays from disk, either from standard or custom formats: genfromtxt
- Creating arrays from raw bytes through the use of strings or buffers
- Use of special library functions (e.g., random)
4.索引:
import numpy as np
x = np.arange(10)
x[0] ##从零开始索引,返回0
x.shape = (2,5)
x[1,2] ##这是与python的list,tuple不同的地方,支持多维的索引,返回7
x[0]等价于x[0,:]
x.shape=(10)
x[2:5] #与python的list一样,支持切片操作;
5.broadcasting:描述的是在进行算术操作时,Array的大小不一致的情况,numpy如何处理;将短的进行扩展,然后进行处理。
>>> a = np.array([1.0, 2.0, 3.0]) >>> b = 2.0 >>> a * b array([ 2., 4., 6.])
When operating on two arrays, NumPy compares their shapes element-wise. It starts with the trailing dimensions, and works its way forward. Two dimensions are compatible when
- they are equal, or
- one of them is 1
[转]大数据:“人工特征工程+线性模型”的尽头
作者是CMU的博士,主页:http://www.cs.cmu.edu/~muli/
11年的时候我加入百度,在凤巢使用机器学习来做广告点击预测。当时非常惊讶于过去两年内训练数据如此疯狂的增长。大家都在热情的谈特征,每次新特征的加入都能立即得到AUC的提升和收入的增长。大家坚信特征才是王道,相信还会有源源不断的特征加入,数据规模还会成倍的增长。我也深受感染,坚定的相信未来两年数据至少还会长十倍,因此一切的工作都围绕这个假设进行。现在两年过去了,回过头来看,当时的预测是正确的吗?


[转] Computer science: The learning machines
文章链接:http://www.nature.com/news/computer-science-the-learning-machines-1.14481
Using massive amounts of data to recognize photos and speech, deep-learning computers are taking a big step towards true artificial intelligence.
Three years ago, researchers at the secretive Google X lab in Mountain View, California, extracted some 10 million still images from YouTube videos and fed them into Google Brain — a network of 1,000 computers programmed to soak up the world much as a human toddler does. After three days looking for recurring patterns, Google Brain decided, all on its own, that there were certain repeating categories it could identify: human faces, human bodies and … cats1.
介绍了 Deep learning的最新 的一些 进展,简单的总结一下:
- Google Brain Project(10^6神经元,10^9连接)代表的Deep learning技术让神经网络复兴;
- Neural Networks(神经网络)模仿人脑的神经元连接,通过经验来更改连接的强度,模拟人类的学习;
- 神经网络可以用来识别图像,处理自然语言,语音识别,翻译语言等;
-
AI的历史:
- 50s:手工提取特征,费事耗力;
- 80-90s:浅层网络“Neural nets were always a delicate art to manage. There is some black magic involved,”
- 2000s:计算能力的增强和数据的爆炸式增长;“For about US$100,000 in hardware, we can build an 11-billion-connection network, with 64 GPUs,”
- 现在 Deep Learning在 语音识别(25%), 图像 识别(ImageNet, 15%),下一步在NLP
Scala基础--控制结构
1.if,while,do while与Java相同;
2.for:
- 遍历集合对象中的每一个元素;
for(i <- 1 to 4) println(i)
- 遍历集合对象中的部分元素:
for(i <- 1 to 4 if i > 2) println(i)
Scala--基本类型和操作
1.类型:Scala的基本类型与Java中的Primitive type对应起来,不过都是首字母大写的类,例如Byte,Short,Int,Long,Char,Float,Double,String,Boolean
2.字面值(literal):在代码中直接写常数值的一种方式。这个Scala与Java基本相同。但是Scala提供Symbol字面值。
val s='type
3.操作:对于大部分操作符来说,与Java相同,但是“==”不同。在Scala中,"=="首先判断“==”左边是否是null,如果不是null然后条用equals方法。
4.Scala给基本类型提供了Rich Wrapper,可以有更加丰富的方法。
[转]机器学习是什么--周志华
Scala学习-类,对象
1.类:类是对象的蓝图,根据类,使用new关键字,就可以创建对象了。和Java一样,Scala的对象也包含:属性和方法。这部分和Java基本上相同。
- 属性:默认是public的,使用private可以改变作用域;
-
方法:定义类的方法与定义普通的相同;Scala没有静态方法。
class ChecksumAccumulator { private var sum = 0 def add(b: Byte) { sum += b } def checksum(): Int = ~ (sum & 0xFF) + 1 }
在Scala的代码中,一个语句如果单独一行的话,可以不加分号,自动进行分号的推断;
- class可以带参数,class Rational(a:Int,b:Int)
- 使用override进行函数重载:
-
class Rational(a:Int,b:Int){ overrride def toString = a + "/" + b } - preconditions:可以使用require()。
class Rational(a:Int, b:Int){
require(b != 0)
val numer:Int = a
val demon:Int = b
override def toString = a + "/" + b
def add(that: Rational) = new Rational(
a * that.demon + b * that.numer,
b * that.demon
)
}
2.使用object定义singleton 对象。
import scala.collection.mutable.Map
object ChecksumAccumulator {
private val cache = Map[String, Int]()
def calculate(s: String): Int =
if (cache.contains(s))
cache(s)
else {
val acc = new ChecksumAccumulator
for (c <- s)
acc.add(c.toByte)
val cs = acc.checksum()
cache += (s -> cs)
cs
}
}
Singleton与class的名字相同,他们得放在同一源文件中,称为companion class 与companion object。不会创建新的类型;与class的名字不同,称为standalone对象,这种对象可以作为一个Scala程序的启动点。
3.Scala程序的启动类似Java,使用含有main方法的Singleton对象。
运行程序的话,首先使用scalac或是fsc进行编译,然后使用scala运行(不含后缀),终于Java的命令行是类似的。
也可是使用Application traits来启动程序,不过这种方法仅仅用在一些简单的,单线程程序中。
Scala-数组,列表,元组和文件读写
已经对Scala的变量,函数了解以后,看一下比较高级的数据结构以及IO。
1.数组:
val language = new Array[String](2) language(0)="Java" language(1)="Scala"
在scala中提供一种更加简洁的方式,
val language = Array("java","Scala")
可以看到,与Java明显不同的是:Scala中数组使用()来索引,而不是使用[]。得到数组里面的每个元素,可以使用:
for(i <- 0 to 2)
println(language(i))
需要注意的是:0 to 2 相当于0.to(2),这个和1+3是一样的道理,所有的操作符都是函数调用的方式进行的。这也是Scala中索引使用(),而不使用[]的原因。language(1)相当于language.apply(1)。
2.Scala的数组长度不可变,但是数组还是可以变化的,比如:
langage(0) = "C"
如果想让数组中元素也不可变,可以使用List。
val l1 = List(1,2) val l2 = List(3,4) val l3 = l1:::l2 val l4 = 2::l2
List是不可变的,符合函数式编程的性质,它有很多操作。
- 构造:List()
- 连接:l1 ::: l2
- 数数:l1.count(e => e>0)
- Map:l1.map(e => e* 2)
- filter: l1.filter(e => e>1)
- foreach: l1.foreach(println)
- 长度:l1.length
- reverse:l1.reverse()
- 排序:l1.sortWith((a,b) => a<b)
- head,last,init,tail
3.Tuple:与List基本一样,但是可以放不同类型的元素;最多可以放22个;索引从1开始,使用._进行索引,比如:t._1
4.set,Map
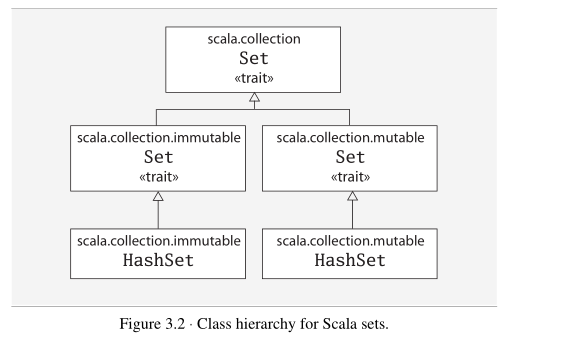
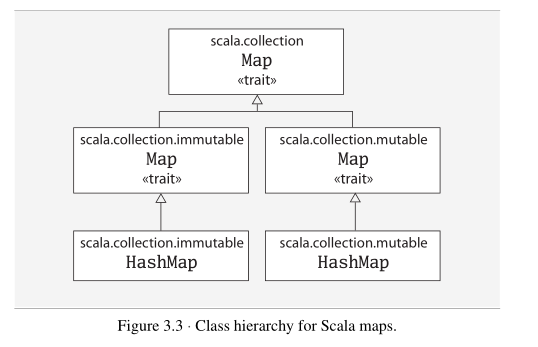
5.读写文件:
import scala.io.Source
for(line <- Source.fromFile(filename).readlines())
println(line)